
System Design là một trong những kỹ năng quan trọng và không thể thiếu đối với bất kỳ ai đang làm việc trong lĩnh vực công nghệ, đặc biệt là các kỹ sư phần mềm. Tuy nhiên, đối với những người mới bắt đầu, khái niệm System Design thường khá trừu tượng và khó tiếp cận.
Bạn có từng tự hỏi làm thế nào các hệ thống lớn như Facebook, Netflix hay Amazon có thể xử lý hàng triệu người dùng mà vẫn hoạt động mượt mà? Những vấn đề như phân tán dữ liệu, cân bằng tải, cache hay thiết kế cơ sở dữ liệu đều là những bài toán thường gặp trong System Design.
Trong bài viết này, chúng ta sẽ cùng khám phá tất tần tật các kiến thức cần thiết về System Design, từ những khái niệm cơ bản đến các kỹ thuật và công cụ phổ biến. Dù bạn là người mới tìm hiểu hay đang chuẩn bị cho các buổi phỏng vấn kỹ sư phần mềm, bài viết này sẽ là tài liệu tham khảo hữu ích để bạn nắm vững nền tảng và tự tin hơn trong hành trình phát triển sự nghiệp.
1/ Tại sao cần học System Design (Thiết Kế Hệ Thống)?
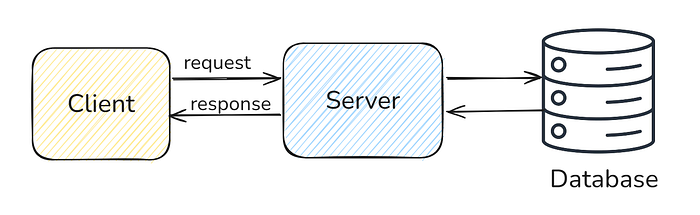
Khi làm các dự án nhỏ, bạn có thể xây dựng ứng dụng backend với NodeJS và cơ sở dữ liệu để xử lý yêu cầu cơ bản. Nhưng trong thực tế, với hàng triệu người dùng, cách làm này không đủ. Bạn cần thiết kế hệ thống để đảm bảo khả năng:
-
Mở rộng: Ứng dụng phải đáp ứng được khi lượng người dùng tăng.
-
Chịu lỗi: Hệ thống vẫn hoạt động khi có lỗi xảy ra.
-
Bảo mật và giám sát: Đảm bảo dữ liệu an toàn và dễ dàng theo dõi trạng thái hoạt động.
2/ Máy chủ là gì?
Máy chủ (server) là máy tính dùng để chạy ứng dụng. Khi bạn chạy ứng dụng NodeJS, nó hoạt động tại địa chỉ như http://localhost:8080, trong đó localhost là cách máy bạn tự nhận diện chính nó.
Khi truy cập một trang web, như https://intech.vietnamworks.com/:
-
Domain intech.vietnamworks.com được dịch thành địa chỉ IP máy chủ thông qua DNS.
-
Yêu cầu được gửi đến địa chỉ IP qua một cổng (port), ví dụ 443 cho HTTPS.
-
Máy chủ xử lý yêu cầu và trả về kết quả.
3/ Làm thế nào để triển khai ứng dụng?
Để đưa ứng dụng lên internet, bạn cần một địa chỉ IP công khai để người khác truy cập. Việc tự quản lý máy chủ khá phức tạp, vì thế mọi người thường thuê máy chủ ảo từ các nhà cung cấp như AWS, Azure, hoặc GCP.
Ví dụ, AWS cung cấp máy ảo (EC2 Instance) có địa chỉ IP công khai. Bạn đưa mã ứng dụng từ máy tính cá nhân lên máy ảo này. Quá trình này gọi là triển khai ứng dụng (deployment).
4/ Latency và Throughput
4.1. Latency (Độ trễ)
Độ trễ là khoảng thời gian cần thiết để một yêu cầu di chuyển từ client (khách hàng) đến server (máy chủ) và quay trở lại, hoặc thời gian để hoàn thành một tác vụ. Đơn vị thường dùng để đo là mili giây (ms).
Ví dụ: Tải một trang web: Nếu mất 200ms để server gửi dữ liệu về trình duyệt, độ trễ sẽ là 200ms.
Hiểu đơn giản:
-
Nếu một trang web tải nhanh, tức là mất ít thời gian hơn, thì độ trễ thấp.
-
Nếu một trang web tải chậm, tức là mất nhiều thời gian hơn, thì độ trễ cao.
RTT (Round Trip Time): Tổng thời gian để một yêu cầu đi từ client đến server và nhận phản hồi quay trở lại. RTT đôi khi được dùng thay thế cho từ "Latency".
4.2. Throughput (Băng thông)
Throughput là số lượng yêu cầu hoặc tác vụ mà hệ thống có thể xử lý trong một giây. Đơn vị đo thường là RPS (Requests Per Second) hoặc TPS (Transactions Per Second).
-
Throughput cao: Hệ thống có thể xử lý nhiều yêu cầu cùng lúc.
-
Throughput thấp: Hệ thống gặp khó khăn khi xử lý nhiều yêu cầu đồng thời.
Tóm lại:
-
Latency đo thời gian xử lý một yêu cầu.
-
Throughput đo số lượng yêu cầu có thể xử lý cùng lúc.
5/ Scaling (Tăng khả năng xử lý)
Khi một website được ra mắt và lưu lượng truy cập tăng đột ngột, hệ thống có thể bị sập. Để tránh điều này, ta cần thực hiện scaling (tăng khả năng xử lý).
Scaling nghĩa là tăng tài nguyên cho hệ thống (như CPU, RAM, bộ nhớ) hoặc thêm nhiều máy chủ để xử lý lưu lượng truy cập lớn hơn.
Ví dụ dễ hiểu:
-
Một chiếc điện thoại giá rẻ với ít RAM và bộ nhớ sẽ bị lag khi bạn chạy nhiều ứng dụng nặng.
-
Tương tự, nếu một server bị quá tải, bạn cần nâng cấp tài nguyên hoặc thêm nhiều server để chia tải.
Hai loại Scaling chính:
- Vertical Scaling (Tăng chiều dọc)
-
Tăng tài nguyên (RAM, CPU, dung lượng lưu trữ) cho một máy chủ duy nhất để xử lý nhiều tải hơn.
-
Loại này thường được dùng cho các cơ sở dữ liệu SQL hoặc ứng dụng stateful (lưu trạng thái) vì việc duy trì trạng thái trong horizontal scaling phức tạp hơn.
- Horizontal Scaling (Tăng chiều ngang)
-
Thay vì tăng tài nguyên cho một máy chủ, ta thêm nhiều máy chủ vào hệ thống và phân phối tải giữa các máy này.
-
Khi vertical scaling đạt đến giới hạn tài nguyên, horizontal scaling là giải pháp tốt hơn.
Ví dụ:
-
Có 8 khách hàng và 2 máy chủ. Bạn chia đều: 4 khách hàng gửi yêu cầu đến máy chủ 1 và 4 khách hàng gửi yêu cầu đến máy chủ 2.
-
Để làm điều này, cần một load balancer (bộ cân bằng tải). Load balancer sẽ nhận các yêu cầu từ khách hàng và phân phối chúng đến máy chủ ít bận nhất.
Thực tế: Phần lớn hệ thống hiện đại đều sử dụng horizontal scaling.
6/ Auto Scaling (Tự động mở rộng)
Giả sử bạn triển khai một website trên nền tảng AWS EC2.
-
Nếu có 10.000 người dùng cùng lúc, bạn cần 10 máy chủ EC2.
-
Nếu tăng lên 100.000 người dùng, bạn cần 100 máy chủ.
Thay vì chạy 100 máy chủ mọi lúc (gây tốn kém chi phí), Auto Scaling sẽ tự động điều chỉnh số lượng máy chủ dựa trên lưu lượng thực tế.
Cách hoạt động:
-
Khi lưu lượng tăng cao, hệ thống sẽ tự động thêm máy chủ để xử lý tải.
-
Khi lưu lượng giảm, hệ thống sẽ giảm số lượng máy chủ để tiết kiệm chi phí.
Ví dụ: Nếu CPU của một máy chủ vượt 90%, hệ thống sẽ tự động tạo thêm máy chủ mới và phân phối tải qua các máy đó.
Tóm lại: Auto Scaling giúp hệ thống luôn vận hành hiệu quả và tiết kiệm chi phí bằng cách tự động thêm hoặc giảm số lượng máy chủ theo nhu cầu thực tế.
7/ Ước tính sơ bộ (Back-of-the-envelope Estimation)
Khi thực hiện horizontal scaling, chúng ta cần ước lượng số lượng server, dung lượng lưu trữ, và tài nguyên cần thiết để xử lý tải. Đây là một bước quan trọng trong thiết kế hệ thống, đặc biệt trong các buổi phỏng vấn thiết kế hệ thống.
Bạn chỉ nên dành khoảng 5 phút cho bước này (không nhiều hơn).
Nguyên tắc: Ước tính chỉ mang tính tương đối để đơn giản hóa tính toán.
Dưới đây là bảng tham khảo nhanh về các giá trị thường gặp:
|
Power of 2 |
Giá trị gần đúng |
Power of 10 |
Tên đầy đủ |
Viết tắt |
|
10 |
1 Nghìn (Thousand) |
3 |
1 Kilobyte |
1 KB |
|
20 |
1 Triệu (Million) |
6 |
1 Megabyte |
1 MB |
|
30 |
1 Tỷ (Billion) |
9 |
1 Gigabyte |
1 GB |
|
40 |
1 Nghìn tỷ (Trillion) |
12 |
1 Terabyte |
1 TB |
|
50 |
1 Triệu tỷ (Quadrillion) |
15 |
1 Petabyte |
1 PB |
Các bước tính toán chính:
7.1. Ước tính tải (Load Estimation)
Ví dụ: Tính toán cho Twitter:
-
Số lượng người dùng hoạt động hàng ngày (DAU): 100 triệu người dùng.
-
Mỗi người dùng đăng 10 tweet mỗi ngày:
∗∗100 triệu×10∗∗ = ∗∗1 tỷ tweet/ngày∗∗**100 triệu × 10** = **1 tỷ tweet/ngày**∗∗100triệu×10∗∗=∗∗1tỷtweet/ngày∗∗
→ Số lượng ghi (writes): 1 tỷ tweet/ngày.
-
Mỗi người dùng đọc 1.000 tweet mỗi ngày:
∗∗100triệu×1.000∗∗=∗∗100tỷ lượtđọc/ngày∗∗**100 triệu × 1.000** = **100 tỷ lượt đọc/ngày**∗∗100triệu×1.000∗∗=∗∗100tỷlượtđọc/ngaˋy∗∗
→ Số lượng đọc (reads): 100 tỷ/ngày.
7.2. Ước tính lưu trữ (Storage Estimation)
Thông tin:
-
Một tweet gồm 200 ký tự (1 ký tự = 2 byte).
-
10% tweet có ảnh (1 ảnh = 2 MB).
Tính toán:
-
Dung lượng 1 tweet không ảnh: 200×2=400 bytes≈500 bytes200 × 2 = 400 \text{ bytes} \approx 500 \text{ bytes}200×2=400 bytes≈500 bytes.
-
Tổng số tweet/ngày: 1 tỷ tweet.
-
Số tweet có ảnh: 10%×1 tỷ=100 triệu tweet10\% × 1 \text{ tỷ} = 100 \text{ triệu tweet}10%×1 tỷ=100 triệu tweet.
Tổng dung lượng lưu trữ cần/ngày:
(500 bytes×1 tỷ)+(2 MB×100 triệu)(500 \text{ bytes} × 1 \text{ tỷ}) + (2 \text{ MB} × 100 \text{ triệu})(500 bytes×1 tỷ)+(2 MB×100 triệu)
Xấp xỉ:
1 TB+1 PB≈1 PB/ngaˋy.1 \text{ TB} + 1 \text{ PB} \approx 1 \text{ PB/ngày}.1 TB+1 PB≈1 PB/ngày.
7.3. Ước tính tài nguyên (Resource Estimation)
Thông tin:
-
Mỗi giây có 10.000 yêu cầu.
-
Mỗi yêu cầu cần 10ms CPU để xử lý.
-
Một CPU core xử lý được 1.000ms/giây.
-
Mỗi server có 4 cores CPU.
Tính toán:
-
Thời gian CPU cần/giây: 10.000×10 ms=100.000 ms/giaˆy.10.000 × 10 \text{ ms} = 100.000 \text{ ms/giây}.10.000×10 ms=100.000 ms/giây.
-
Số lượng cores cần: 100.000/1.000=100 cores.100.000 / 1.000 = 100 \text{ cores}.100.000/1.000=100 cores.
-
Số lượng server cần: 100/4=25 servers.100 / 4 = 25 \text{ servers}.100/4=25 servers.
→ Cần 25 server với một load balancer phía trước để phân phối yêu cầu.
8/ CAP Theorem (Định lý CAP)
Định lý CAP chỉ ra sự đánh đổi giữa Consistency (Tính nhất quán), Availability (Tính sẵn sàng), và Partition Tolerance (Khả năng chịu phân vùng) trong hệ thống phân tán.
Ba thành phần của CAP:
- Consistency (Nhất quán): Mọi yêu cầu đọc trả về kết quả giống nhau bất kể đọc từ node nào.
- Availability (Sẵn sàng): Hệ thống luôn phản hồi được yêu cầu, ngay cả khi một số node gặp sự cố.
- Partition Tolerance (Chịu phân vùng): Hệ thống vẫn hoạt động dù xảy ra lỗi kết nối mạng giữa các node.
Lưu ý: Trong một hệ thống phân tán, Partition Tolerance luôn là yếu tố bắt buộc, vì lỗi mạng là không thể tránh khỏi.
Nếu xảy ra lỗi phân vùng:
-
Ưu tiên Availability: Các node vẫn phục vụ yêu cầu nhưng có thể dẫn đến dữ liệu không nhất quán.
-
Ưu tiên Consistency: Hệ thống dừng nhận yêu cầu cho đến khi các node đồng bộ dữ liệu.
Lựa chọn giữa CP và AP:
-
CP (Consistency + Partition Tolerance):
→ Dùng cho hệ thống yêu cầu dữ liệu chính xác như ngân hàng, giao dịch tài chính. -
AP (Availability + Partition Tolerance):
→ Dùng cho hệ thống như mạng xã hội, nơi dữ liệu nhất quán không quá quan trọng.
Ví dụ:
-
CP: Giao dịch ngân hàng không thể xử lý nếu dữ liệu chưa nhất quán.
-
AP: Like count trên bài đăng mạng xã hội có thể không chính xác ngay lập tức mà không gây vấn đề lớn.
8/ Mở rộng cơ sở dữ liệu (Scaling of Database)
Thông thường, bạn sẽ có một máy chủ cơ sở dữ liệu duy nhất; ứng dụng của bạn truy vấn từ cơ sở dữ liệu này và nhận kết quả.
Khi bạn đạt đến một quy mô nhất định, máy chủ cơ sở dữ liệu này có thể bắt đầu phản hồi chậm hoặc thậm chí ngừng hoạt động vì các hạn chế của nó. Khi đó, làm sao để mở rộng cơ sở dữ liệu sẽ là vấn đề cần giải quyết, và chúng ta sẽ nghiên cứu trong phần này.
Chúng ta sẽ mở rộng cơ sở dữ liệu từng bước. Điều này có nghĩa là nếu bạn chỉ có 10.000 người dùng, việc mở rộng để hỗ trợ 10 triệu người dùng là một sự thừa thãi và là việc thiết kế quá phức tạp. Chúng ta chỉ mở rộng cho đến giới hạn đủ cho doanh nghiệp của mình.
Các phương pháp mở rộng cơ sở dữ liệu
8.1. Chỉ mục hóa (Indexing)
Trước khi chỉ mục hóa, cơ sở dữ liệu phải kiểm tra từng hàng trong bảng để tìm dữ liệu của bạn, điều này gọi là quét toàn bảng (full table scan) và có thể chậm đối với các bảng lớn. Việc này mất thời gian theo công thức O(N).
Với việc chỉ mục hóa, cơ sở dữ liệu sử dụng chỉ mục để nhảy trực tiếp đến các hàng cần thiết, giúp việc tìm kiếm nhanh hơn nhiều.
Nếu bạn chỉ mục hóa cột "id", cơ sở dữ liệu sẽ tạo một bản sao của cột "id" trong một cấu trúc dữ liệu gọi là B-tree. Nó sử dụng B-tree để tìm kiếm id cụ thể. Việc tìm kiếm sẽ nhanh hơn nhờ các id được sắp xếp theo cách mà bạn có thể áp dụng tìm kiếm nhị phân để tìm kiếm trong thời gian O(logN).
Nếu bạn muốn kích hoạt chỉ mục cho bất kỳ cột nào, bạn chỉ cần thêm một dòng lệnh, và tất cả các công việc như tạo B-tree sẽ được cơ sở dữ liệu xử lý cho bạn. Bạn không cần phải lo lắng về bất cứ điều gì.
Đây là một giải thích ngắn gọn và đơn giản về chỉ mục hóa.
8.2. Phân vùng (Partitioning)
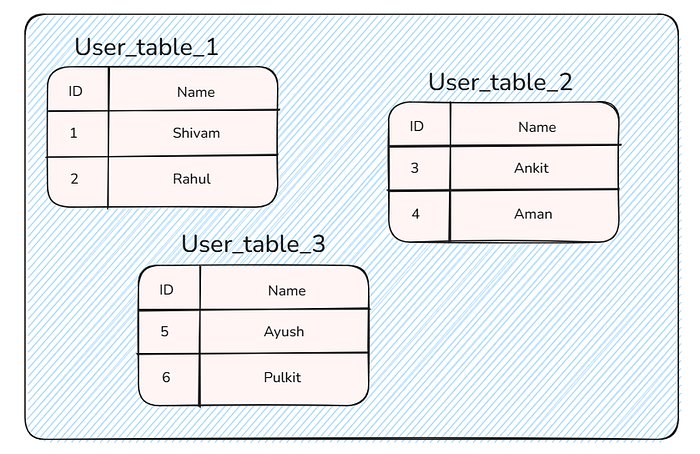
Phân vùng có nghĩa là chia bảng lớn thành nhiều bảng nhỏ.
Bạn có thể thấy rằng chúng ta đã chia bảng người dùng thành 3 bảng:
-
user_table_1
-
user_table_2
-
user_table_3
Những bảng này được lưu trong cùng một máy chủ cơ sở dữ liệu.
Lợi ích của phân vùng: Khi tệp chỉ mục của bạn trở nên rất lớn, nó sẽ bắt đầu gặp phải một số vấn đề về hiệu suất khi tìm kiếm trong tệp chỉ mục lớn đó. Nhưng sau khi phân vùng, mỗi bảng có chỉ mục riêng, do đó việc tìm kiếm trên các bảng nhỏ hơn sẽ nhanh hơn.
Bạn có thể tự hỏi làm thế nào để biết nên truy vấn từ bảng nào. Đừng lo lắng, bạn vẫn có thể sử dụng cùng một truy vấn như trước, ví dụ: SELECT * FROM users WHERE ID=4. PostgreSQL rất thông minh, nó sẽ tìm bảng phù hợp và trả về kết quả. Tuy nhiên, bạn cũng có thể viết cấu hình này ở cấp ứng dụng nếu muốn.
8.3. Kiến trúc Master-Slave
Sử dụng phương pháp này khi bạn gặp phải nghẽn cổ chai, ví dụ: ngay cả khi đã thực hiện chỉ mục hóa, phân vùng và mở rộng dọc mà truy vấn vẫn chậm hoặc cơ sở dữ liệu không thể xử lý thêm yêu cầu trên một máy chủ duy nhất.
Trong cấu hình này, bạn sao chép dữ liệu vào nhiều máy chủ thay vì chỉ một.
Khi bạn thực hiện yêu cầu đọc (SELECT queries), yêu cầu sẽ được chuyển hướng đến máy chủ ít bận rộn nhất. Nhờ vậy, bạn có thể phân phối tải.
Tuy nhiên, tất cả yêu cầu ghi (INSERT, UPDATE, DELETE) chỉ được xử lý bởi một máy chủ.
Máy chủ xử lý yêu cầu ghi được gọi là Master Node.
Các máy chủ xử lý yêu cầu đọc được gọi là Slave Nodes.
Khi bạn thực hiện yêu cầu ghi, dữ liệu được xử lý và ghi vào máy chủ master, sau đó được sao chép (asynchronously hoặc synchronously tùy cấu hình) sang tất cả các slave nodes.
8.4. Cấu hình Multi-master
Khi các truy vấn ghi trở nên chậm hoặc một máy chủ master không thể xử lý tất cả yêu cầu ghi, bạn sẽ chuyển sang phương pháp này.
Trong cấu hình này, thay vì một máy chủ master duy nhất, bạn sử dụng nhiều cơ sở dữ liệu master để xử lý các yêu cầu ghi.
Ví dụ: Một cấu hình rất phổ biến là đặt hai máy chủ master, một cho miền Bắc Ấn Độ và một cho miền Nam Ấn Độ. Tất cả yêu cầu ghi từ miền Bắc sẽ được xử lý bởi North-India-DB, và các yêu cầu ghi từ miền Nam sẽ được xử lý bởi South-India-DB. Các dữ liệu của chúng sẽ được đồng bộ (hoặc sao chép) định kỳ.
Trong cấu hình multi-master, phần khó khăn nhất là xử lý các xung đột. Nếu cùng một ID có hai dữ liệu khác nhau trong cả hai master, bạn phải viết logic trong mã để xác định xem bạn muốn chấp nhận cả hai, ghi đè dữ liệu cũ bằng dữ liệu mới nhất, nối dữ liệu lại với nhau, v.v. Điều này hoàn toàn phụ thuộc vào tình huống sử dụng của doanh nghiệp.
8.5. Sharding (Phân mảnh cơ sở dữ liệu)
Sharding là một phương pháp phức tạp. Hãy tránh sử dụng nó trong thực tế và chỉ áp dụng khi tất cả các phương pháp trên không đủ và bạn cần mở rộng hơn nữa.
Sharding tương tự như phân vùng, nhưng thay vì đặt các bảng khác nhau vào cùng một máy chủ, bạn đặt chúng vào các máy chủ khác nhau.
Ví dụ: Chúng ta cắt bảng thành 3 phần và đặt chúng vào 3 máy chủ khác nhau. Những máy chủ này thường được gọi là shards.
Sharding được thực hiện dựa trên cột ID, cột này được gọi là sharding key.
Lưu ý: Sharding key nên phân phối dữ liệu đều trên các shard để tránh làm quá tải một shard đơn lẻ.
Mỗi phân vùng sẽ được lưu trên một máy chủ cơ sở dữ liệu độc lập (gọi là shard). Nhờ vậy, bạn có thể mở rộng từng máy chủ này theo nhu cầu của mình, ví dụ: áp dụng kiến trúc master-slave cho một trong các shard nếu nó nhận nhiều yêu cầu.
Chiến lược Sharding
a, Sharding dựa trên phạm vi (Range-Based Sharding):
- Dữ liệu được chia thành các shard dựa trên phạm vi giá trị của khóa sharding. Ví dụ:
-
Shard 1: Người dùng có user_id từ 1–1000.
-
Shard 2: Người dùng có user_id từ 1001–2000.
-
Shard 3: Người dùng có user_id từ 2001–3000.
- Ưu điểm: Dễ triển khai.
- Nhược điểm: Phân phối không đều nếu dữ liệu bị lệch (ví dụ, một số phạm vi có nhiều người dùng hơn).
b, Sharding dựa trên hàm băm (Hash-Based Sharding): Áp dụng hàm băm lên khóa sharding, kết quả sẽ xác định shard. Ví dụ: HASH(user_id) % number_of_shards xác định shard.
-
Ưu điểm: Đảm bảo phân phối dữ liệu đều.
-
Nhược điểm: Khó tái cân bằng khi thêm shard mới, vì kết quả băm sẽ thay đổi.
c, Sharding dựa trên khu vực (Geographic/Entity-Based Sharding): Dữ liệu được chia theo nhóm logic, chẳng hạn như khu vực hoặc phòng ban. Ví dụ:
-
Shard 1: Người dùng từ Mỹ.
-
Shard 2: Người dùng từ Châu Âu.
- Ưu điểm: Hữu ích cho các hệ thống phân tán theo khu vực.
- Nhược điểm: Một số shard có thể trở thành "nút nóng" với lưu lượng không đều.
d, Sharding dựa trên thư mục (Directory-Based Sharding):
Một bảng tra cứu giữ bản đồ giữa các shard và dữ liệu trong đó. Ví dụ: Một bảng tra cứu ánh xạ phạm vi user_id với shard_id.
-
Ưu điểm: Linh hoạt trong việc chuyển nhượng shard mà không thay đổi logic ứng dụng.
-
Nhược điểm: Thư mục có thể trở thành điểm nghẽn.
Nhược điểm của Sharding
a, Khó triển khai: Bạn phải tự viết code để xác định shard nào cần truy vấn hoặc ghi dữ liệu. Điều này đòi hỏi nhiều công sức và phức tạp hơn so với các cách mở rộng khác.
b, Tốn kém khi thực hiện JOIN: Vì dữ liệu được chia nhỏ và lưu trên các máy chủ khác nhau, khi thực hiện JOIN, hệ thống phải lấy dữ liệu từ nhiều shard để kết hợp lại, dẫn đến tốn thời gian và tài nguyên.
c, Mất tính nhất quán: Do dữ liệu được phân tán trên nhiều máy chủ, việc đảm bảo tính nhất quán giữa các shard trở nên rất khó khăn
Tóm tắt về mở rộng cơ sở dữ liệu (Database Scaling)
Sau khi tìm hiểu, đây là các quy tắc cơ bản để mở rộng cơ sở dữ liệu:
a, Ưu tiên mở rộng dọc (Vertical Scaling): Đây là cách đơn giản nhất. Bạn chỉ cần nâng cấp cấu hình máy chủ (CPU, RAM, ổ cứng). Nếu máy chủ đã đạt giới hạn tối đa, hãy chuyển sang các phương pháp khác.
b, Khi hệ thống có lưu lượng đọc cao: Sử dụng kiến trúc master-slave, nơi một máy chủ chính (master) xử lý ghi, còn các máy chủ phụ (slave) xử lý đọc.
c, Khi hệ thống có lưu lượng ghi cao: Sử dụng sharding để chia nhỏ dữ liệu ra nhiều máy chủ khác nhau. Tuy nhiên, hãy cố gắng hạn chế các truy vấn cần lấy dữ liệu từ nhiều shard (cross-shard queries), vì nó làm giảm hiệu năng.
d, Khi hệ thống có lưu lượng đọc cực cao và kiến trúc master-slave không đủ: Lúc này, bạn có thể kết hợp thêm sharding để giảm tải đọc. Nhưng chỉ thực hiện khi hệ thống đạt đến quy mô rất lớn và cần mở rộng hơn nữa.
9. SQL vs NoSQL Databases: Khi nào nên sử dụng loại nào?
9.1. SQL Database (Cơ sở dữ liệu quan hệ)
-
Lưu trữ: Dữ liệu được lưu dưới dạng bảng (tables).
-
Schema cố định: Bạn phải định nghĩa cấu trúc dữ liệu (bảng, cột, kiểu dữ liệu) trước khi thêm dữ liệu vào.
-
Đảm bảo tính toàn vẹn dữ liệu: Tuân theo tính chất ACID (Atomicity, Consistency, Isolation, Durability), đảm bảo dữ liệu luôn chính xác và đáng tin cậy.
-
Ví dụ: MySQL, PostgreSQL, Oracle, SQL Server, SQLite.
9.2. NoSQL Database (Cơ sở dữ liệu phi quan hệ)
- Phân loại:
-
Document-based: Lưu dữ liệu dưới dạng tài liệu, như JSON hoặc BSON. (Ví dụ: MongoDB).
-
Key-value stores: Lưu dữ liệu dưới dạng cặp khóa-giá trị. (Ví dụ: Redis, AWS DynamoDB).
-
Column-family stores: Lưu dữ liệu theo cột thay vì theo hàng. (Ví dụ: Apache Cassandra).
-
Graph databases: Tập trung vào mối quan hệ giữa dữ liệu, thường dùng trong mạng xã hội. (Ví dụ: Neo4j).
- Schema linh hoạt: Cho phép thêm dữ liệu mà không cần tuân theo cấu trúc đã định trước.
- Ưu tiên hiệu năng và khả năng mở rộng: Không tuân theo tính chất ACID nghiêm ngặt.
9.3. Khả năng mở rộng của SQL và NoSQL
- SQL:
-
Chủ yếu hỗ trợ mở rộng dọc (vertical scaling): Nâng cấp phần cứng của một máy chủ duy nhất (CPU, RAM, dung lượng).
-
Có thể thực hiện sharding, nhưng thường hạn chế vì SQL cần đảm bảo tính toàn vẹn dữ liệu, và việc thực hiện JOIN trên các shard rất phức tạp và tốn kém.
- NoSQL:
-
Chủ yếu hỗ trợ mở rộng ngang (horizontal scaling): Thêm nhiều máy chủ (node) vào cụm (cluster) để xử lý khối lượng dữ liệu lớn.
-
Sharding thường được sử dụng để phân tán dữ liệu giữa các máy chủ.
9.4. Khi nào nên sử dụng SQL hoặc NoSQL?
- NoSQL:
-
Ví dụ: Đánh giá sản phẩm, đề xuất trong ứng dụng thương mại điện tử.
-
Ví dụ: Bài viết, lượt thích, bình luận trên mạng xã hội; vị trí tài xế thời gian thực trong ứng dụng giao hàng.
-
Khi dữ liệu không có cấu trúc hoặc cần schema linh hoạt.
-
Khi cần khả năng mở rộng cao, xử lý lượng dữ liệu lớn và giảm độ trễ.
- SQL:
- Ví dụ: Bảng tài khoản khách hàng của ứng dụng thương mại điện tử.
- Ví dụ: Giao dịch tài chính, số dư tài khoản ngân hàng; đơn hàng, thanh toán trong ứng dụng thương mại điện tử.
- Khi dữ liệu có cấu trúc và schema cố định.
- Khi cần đảm bảo tính toàn vẹn và nhất quán dữ liệu (ACID).
- Khi cần thực hiện truy vấn phức tạp, JOIN và tổng hợp dữ liệu, đặc biệt trong phân tích dữ liệu.
9.5. Monolith và Microservices
Monolith (Ứng dụng nguyên khối):
-
Toàn bộ ứng dụng được xây dựng dưới dạng một khối duy nhất.
-
Ví dụ: Ứng dụng thương mại điện tử với tất cả các chức năng (quản lý người dùng, danh sách sản phẩm, đơn hàng, thanh toán) trong một backend duy nhất.
Microservices:
-
Chia ứng dụng lớn thành các dịch vụ nhỏ hơn, độc lập và dễ quản lý.
-
Ví dụ:
-
User Service: Quản lý người dùng.
-
Product Service: Quản lý sản phẩm.
-
Order Service: Quản lý đơn hàng.
-
Payment Service: Quản lý thanh toán.
Lợi ích của Microservices
-
Khả năng mở rộng độc lập: Nếu một dịch vụ nhận lưu lượng truy cập lớn, bạn chỉ cần mở rộng dịch vụ đó mà không ảnh hưởng đến các dịch vụ khác.
-
Linh hoạt trong công nghệ: Các dịch vụ có thể được xây dựng bằng các công nghệ khác nhau. Ví dụ: User Service sử dụng Node.js, còn Order Service sử dụng Golang.
-
Giảm tác động của lỗi: Nếu một dịch vụ gặp sự cố (ví dụ: Order Service bị sập), các dịch vụ khác (như User Service hoặc Product Service) vẫn hoạt động bình thường.
9.6. Khi nào nên sử dụng Microservices?
-
Khi công ty có nhiều đội ngũ làm việc độc lập trên các chức năng khác nhau, mỗi đội có thể đảm nhận một microservice.
-
Khi muốn tránh điểm lỗi duy nhất (single point of failure), tránh trường hợp một lỗi ảnh hưởng toàn bộ ứng dụng.
9.7. API Gateway trong Microservices
-
Chức năng:
-
Nhận tất cả các yêu cầu từ client và chuyển đến đúng dịch vụ.
-
Thay vì sử dụng nhiều địa chỉ IP cho từng microservice, bạn chỉ cần sử dụng một endpoint duy nhất.
-
Lợi ích:
-
Rate Limiting: Kiểm soát lưu lượng truy cập.
-
Caching: Lưu trữ dữ liệu để tăng tốc độ phản hồi.
-
Bảo mật: Xác thực và phân quyền.
10. Load Balancer
10.1. Tại sao cần Load Balancer?
Trong mô hình mở rộng ngang (horizontal scaling), chúng ta thường sử dụng nhiều máy chủ (servers) để xử lý yêu cầu. Tuy nhiên, không thể cung cấp tất cả địa chỉ IP của các máy này cho khách hàng (client) và để họ tự quyết định gửi yêu cầu đến máy nào.
Load Balancer là giải pháp:
-
Hoạt động như điểm liên lạc duy nhất giữa client và hệ thống.
-
Client gửi yêu cầu tới tên miền của Load Balancer. Load Balancer sẽ phân phối yêu cầu đến một trong các máy chủ đang ít bận nhất.
10.2. Thuật toán của Load Balancer
a. Thuật toán Round Robin
- Cách hoạt động:
-
-
Với 3 máy chủ (Server-1, Server-2, Server-3):
-
Yêu cầu đầu tiên → Server-1
-
Yêu cầu thứ hai → Server-2
-
Yêu cầu thứ ba → Server-3
-
Yêu cầu thứ tư → Quay lại Server-1
-
Tiếp tục theo vòng lặp.
-
-
Phân phối yêu cầu lần lượt theo thứ tự vòng tròn đến các máy chủ.
-
-
Ưu điểm:
-
Đơn giản, dễ triển khai.
-
Hiệu quả nếu tất cả máy chủ có năng lực tương đương.
-
-
Nhược điểm: Không quan tâm đến tình trạng tải hoặc sức khỏe của máy chủ.
b. Thuật toán Weighted Round Robin
-
Cách hoạt động:
-
Tương tự như Round Robin, nhưng mỗi máy chủ được gán trọng số (weight) dựa trên năng lực (RAM, lưu trữ, v.v.).
-
Máy chủ có trọng số cao hơn sẽ nhận được nhiều yêu cầu hơn.
-
Ví dụ:
-
Server-1 và Server-2 có trọng số là 1.
-
Server-3 có trọng số là 2 (có năng lực lớn hơn).
-
Phân phối yêu cầu: Server-1 → Server-2 → Server-3 → Server-3 → Server-1 → Server-2 → ...
-
-
Với 3 máy chủ:
-
Ưu điểm: Xử lý tốt khi các máy chủ có năng lực không đồng đều.
-
Nhược điểm: Trọng số tĩnh (static weights) không phản ánh hiệu năng thực tế theo thời gian thực.
c. Thuật toán Least Connections
-
Cách hoạt động:
-
Chuyển hướng yêu cầu đến máy chủ có ít kết nối đang hoạt động nhất.
-
"Kết nối" ở đây có thể là HTTP, TCP, WebSocket, v.v.
-
Ưu điểm: Cân bằng tải động dựa trên trạng thái hoạt động thời gian thực của máy chủ.
-
Nhược điểm: Hoạt động không hiệu quả nếu thời lượng kết nối giữa các yêu cầu khác nhau quá lớn.
d. Thuật toán Hash-Based
-
Cách hoạt động:
-
Load Balancer sử dụng một giá trị đầu vào, như địa chỉ IP của client, user_id, v.v., để tính toán hàm băm (hash).
-
Kết quả băm sẽ quyết định máy chủ nào nhận yêu cầu, đảm bảo một client cụ thể luôn được kết nối đến cùng một máy chủ (session persistence).
-
Ưu điểm: Hữu ích trong việc duy trì phiên làm việc (session persistence).
-
Nhược điểm: Khi thay đổi số lượng máy chủ (thêm/xóa), hàm băm có thể bị gián đoạn, gây mất tính nhất quán trong phiên làm việc.
11/ Caching
11.1. Giới thiệu về Caching
Caching là quá trình lưu trữ dữ liệu được truy cập thường xuyên vào một lớp lưu trữ tốc độ cao để các yêu cầu sau đó có thể được xử lý nhanh hơn. Ví dụ:
-
Một đoạn dữ liệu mất 500ms để truy vấn từ MongoDB và thêm 100ms để tính toán trên backend trước khi gửi đến client. Tổng thời gian là 600ms.
-
Nếu lưu dữ liệu đã tính toán này vào Redis và phục vụ từ đó, thời gian phản hồi có thể giảm từ 600ms xuống còn 60ms (các con số chỉ mang tính minh họa).
Caching nghĩa là lưu trữ dữ liệu đã xử lý trước vào một hệ thống lưu trữ truy cập nhanh như Redis. Khi người dùng yêu cầu dữ liệu, nó được cung cấp từ Redis thay vì truy vấn trực tiếp từ cơ sở dữ liệu. Ứng dụng:
-
Một trang blog có đường dẫn /blogs để hiển thị danh sách blog.
-
Lần đầu truy cập, dữ liệu không có trong cache nên được lấy từ cơ sở dữ liệu (mất khoảng 800ms).
-
Sau đó, dữ liệu được lưu vào Redis. Những lần tiếp theo, dữ liệu được trả về từ Redis với thời gian phản hồi chỉ 20ms.
Vấn đề: Khi có bài blog mới, cần làm mới dữ liệu trong Redis. Đây gọi là Cache Invalidation. Có thể thực hiện bằng cách thiết lập thời gian sống (TTL) cho cache. Ví dụ: Sau mỗi 24 giờ, Redis tự động xóa dữ liệu.
Lợi ích của Caching
- Cải thiện hiệu suất: Giảm độ trễ (latency) cho người dùng.
- Giảm tải: Giảm bớt áp lực lên cơ sở dữ liệu backend.
- Tiết kiệm chi phí: Giảm sử dụng tài nguyên mạng và máy tính.
- Khả năng mở rộng: Hỗ trợ tốt hơn cho tải lưu lượng cao.
11.2. Các loại Cache
- Client-Side Cache:
-
Lưu trữ trên thiết bị của người dùng (ví dụ: bộ nhớ cache trình duyệt).
-
Giảm số lượng yêu cầu tới server và tiết kiệm băng thông.
-
Ví dụ: HTML, CSS, JavaScript.
- Server-Side Cache:
-
Lưu trữ trên máy chủ.
-
Ví dụ: Redis, Memcached.
- CDN Cache:
-
Dành cho nội dung tĩnh (HTML, CSS, PNG, MP4, v.v.).
-
Lưu trữ trên các máy chủ phân phối toàn cầu.
-
Ví dụ: AWS CloudFront, Cloudflare.
- Application-Level Cache:
-
Tích hợp trong mã ứng dụng.
-
Cache các kết quả trung gian hoặc kết quả truy vấn cơ sở dữ liệu.
11.3. Tìm hiểu sâu về Redis
a. Redis là gì?
Redis là một kho lưu trữ dữ liệu cấu trúc trong bộ nhớ (in-memory data structure store).
-
Ưu điểm: Dữ liệu được lưu trong RAM → tốc độ đọc/ghi cực nhanh so với ổ đĩa.
-
So sánh với cơ sở dữ liệu:
-
Redis nhanh hơn vì dùng RAM.
-
Tuy nhiên, RAM có giới hạn dung lượng, do đó không thể lưu trữ toàn bộ dữ liệu trong Redis.
b. Cách lưu trữ trong Redis
Redis lưu trữ dữ liệu dưới dạng cặp key-value.
-
Key: Là tên của dữ liệu.
-
Value: Giá trị của dữ liệu, có thể là nhiều loại như chuỗi (string), danh sách (list), v.v.
c. Các loại dữ liệu phổ biến trong Redis
- String:
-
SET key value: Lưu dữ liệu với một giá trị cụ thể.
-
GET key: Lấy giá trị liên kết với key.
-
SET key value NX: Lưu giá trị nếu key chưa tồn tại.
-
MGET key1 key2: Lấy nhiều giá trị cùng lúc.

- List:
-
LPUSH key value: Thêm giá trị vào đầu danh sách.
-
RPUSH key value: Thêm giá trị vào cuối danh sách.
-
LLEN key: Đếm số lượng phần tử trong danh sách.
-
LPOP key: Lấy và xóa giá trị đầu tiên.
-
RPOP key: Lấy và xóa giá trị cuối cùng.
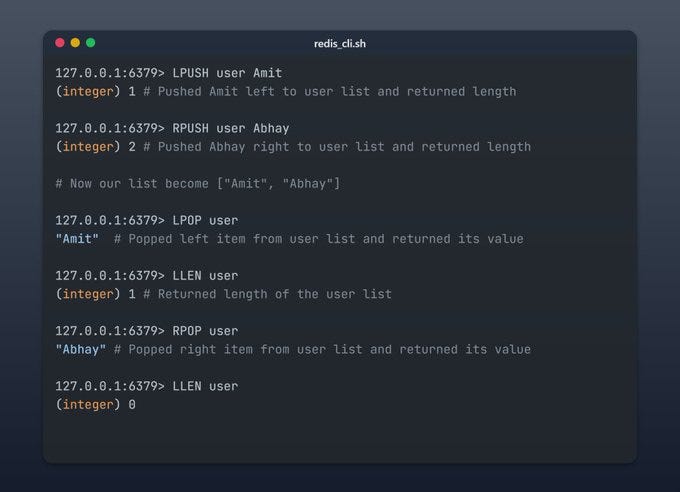
d. Ứng dụng thực tế
-
Queue (hàng đợi): Sử dụng LPUSH và RPOP (FIFO - First In First Out).
-
Stack (ngăn xếp): Sử dụng LPUSH và LPOP (LIFO - Last In First Out).
e. Redis trong thực tế
- Cách triển khai:
Sử dụng Docker để chạy Redis:docker run -d --name redis-stack -p 6379:6379 -p 8001:8001 redis/redis-stack:latest
- Ví dụ về ứng dụng blog:
-
Lần đầu người dùng truy cập /blogs, dữ liệu được lấy từ cơ sở dữ liệu.
-
Sau đó, dữ liệu được lưu vào Redis với TTL là 24 giờ.
-
Các lần truy cập tiếp theo, dữ liệu được trả về từ Redis thay vì truy vấn cơ sở dữ liệu.
- Cập nhật đồng bộ: Khi cơ sở dữ liệu được ghi, Redis cũng được cập nhật ngay lập tức. Ví dụ: Trong các cuộc thi trực tuyến (như Codeforces), bảng xếp hạng được cập nhật đồng thời trên cơ sở dữ liệu và Redis để đảm bảo người dùng luôn thấy dữ liệu mới nhất.
Học và triển khai Redis
-
Tài liệu Redis: Redis Docs
-
Thư viện tích hợp Redis:
-
Node.js: ioredis
-
Django: django-redis
Lời kết
System Design không chỉ là một kỹ năng mà còn là một nghệ thuật, đòi hỏi sự kết hợp giữa tư duy logic, khả năng giải quyết vấn đề và kinh nghiệm thực tiễn. Những kiến thức và khái niệm trong bài viết này chỉ là bước khởi đầu, giúp bạn có cái nhìn tổng quan và hiểu rõ hơn về cách các hệ thống lớn được thiết kế và vận hành.
VietnamWorks inTECH hy vọng bài viết này đã mang đến cho bạn những giá trị thiết thực. Hãy bắt đầu áp dụng những gì đã học vào các dự án thực tế, từ những bài toán nhỏ đến những hệ thống phức tạp hơn.





