
Hãy tưởng tượng thế này: bạn viết một tập lệnh để xử lý một số dữ liệu trên máy tính xách tay của mình, đi uống cà phê và khi bạn quay lại sau 15 phút, công việc chỉ hoàn thành được 10%.
Tại sao nó lại chậm như vậy? Phần nào chậm? Nó đang đọc, xử lý hay lưu dữ liệu? Làm thế nào để tôi làm cho nó nhanh hơn? Nó có thực sự chậm không?
Trong bài viết này, VietnamWorks inTECH sẽ giới thiệu một công cụ sẽ giúp bạn trả lời tất cả những câu hỏi này có tên là Profiler.
1. Profiler là gì?
Profiler là một công cụ hoạt động bằng cách lấy code của bạn, chạy nó, và thu thập thông tin về thời gian thực hiện của mỗi lần gọi hàm, số lần mỗi hàm được thực thi, và thứ tự các hàm được gọi. Bằng cách phân tích đầu ra của profiler, bạn có thể tìm ra phần nào trong code của bạn chiếm nhiều thời gian chạy nhất (được gọi là bottleneck) và thậm chí có thể đưa ra ý tưởng về cách cải thiện tốc độ tổng thể lớn nhất.
Giả sử chúng ta có một tệp văn bản lớn và muốn tìm số lần xuất hiện của một mẫu nhất định trong đó. Trước tiên, hãy tạo một tệp lớn gồm các ký tự ngẫu nhiên (theo từng dòng):
import random
import string
def generate_random_string(length):
"""Generate a random string of lowercase letters and digits."""
letters_and_digits = string.ascii_letters + string.digits
return ''.join(random.choice(letters_and_digits) for _ in range(length))
def generate_random_file(filename, num_lines, line_length):
"""Generate a file of random lines with the given number and length."""
with open(filename, 'w') as f:
for i in range(num_lines):
random_line = generate_random_string(line_length) + '\n'
f.write(random_line)
if __name__ == '__main__':
# generate 1,000,000 lines of 1000 characters each
generate_random_file('random.txt', 1_000_000, 1000)
Tiếp theo, hãy định nghĩa hàm cơ bản của chúng ta — nó đọc một tệp từng dòng, sau đó đếm số lần xuất hiện của các từ "bob" và "rob" có một chữ số đứng trước:
import re
def baseline():
num_total_matches = 0
pattern1 = r"[0-9]{1}bob"
pattern2 = r"[0-9]{1}rob"
with open('random.txt', 'rt') as f:
for line in f:
line = line.lower() # make sure our text is all lowercase
for pattern in [pattern1, pattern2]:
# Find all occurrences of the pattern in the string
matches = re.findall(pattern, line)
# Count the number of matches
num_matches = len(matches)
num_total_matches += num_matches
return num_total_matches
Chẳng hạn, dòng văn bản "abc1robdef02bob" có chứa mẫu "rob" xuất hiện hai lần.
Chúng ta chạy hàm cơ sở, tính toán số lần xuất hiện (trong trường hợp này là 10861), và đo thời gian chạy - 32 giây.
Vậy làm thế nào để tăng tốc độ tìm kiếm?
2. Mục tiêu cải tiến tiềm năng
Bốn yếu tố tiềm ẩn khiến đoạn mã chạy chậm:
-
Sử dụng chuỗi raw thay vì đối tượng biểu thức chính quy được biên dịch
-
Sử dụng hai phép tìm kiếm riêng biệt thay vì một biểu thức chính quy đơn
-
Chuyển đổi mọi dòng thành chữ thường thay vì sử dụng flag không phân biệt chữ hoa chữ thường
-
Đọc file từng dòng thay vì đọc theo block lớn hơn

3. Python Profilers
Tin vui là bạn không cần phải tự mình thực hiện bất kỳ điều gì. Python đã có sẵn hai module profiling tích hợp - cProfile và profile. Chúng có cùng chức năng nhưng cProfile được viết bằng C, còn profile được viết bằng Python thuần túy, bạn có thể sử dụng chúng trực tiếp. Tuy nhiên, chúng ta sẽ đơn giản hóa rất nhiều thứ bằng cách sử dụng một vài công cụ bên ngoài - đưa ra một cách nhanh chóng và tiện lợi để profile một phần của code (ví dụ như một hàm) và lưu kết quả vào file.
Một trong số đó chính là module tên profilehooks, cung cấp một decorator đơn giản mà có thể bao bọc xung quanh hàm như thế này:
from profilehooks import profile
# stdout=False -> don't print anything in the terminal
# filname -> path to the output file with profiling results
def baseline():
...
Nó có thể được cài đặt bằng lệnh đơn giản pip install profilehooks.
Ngoài ra, chúng ta cần hiển thị file này theo cách dễ đọc. Chúng ta sẽ sử dụng hai công cụ sau cho việc này:
3.1. SnakeViz - Nhanh và đơn giản
Snakeviz là một công cụ trực quan hiển thị kết quả profiling của Python, có thể hoạt động trên trình duyệt của bạn. Việc cài đặt ( pip install snakeviz) và sử dụng ( snakeviz <path-to-profiling-output>) cực kỳ đơn giản. Hãy xem kết quả profiling của hàm baseline của chúng ta là gì.

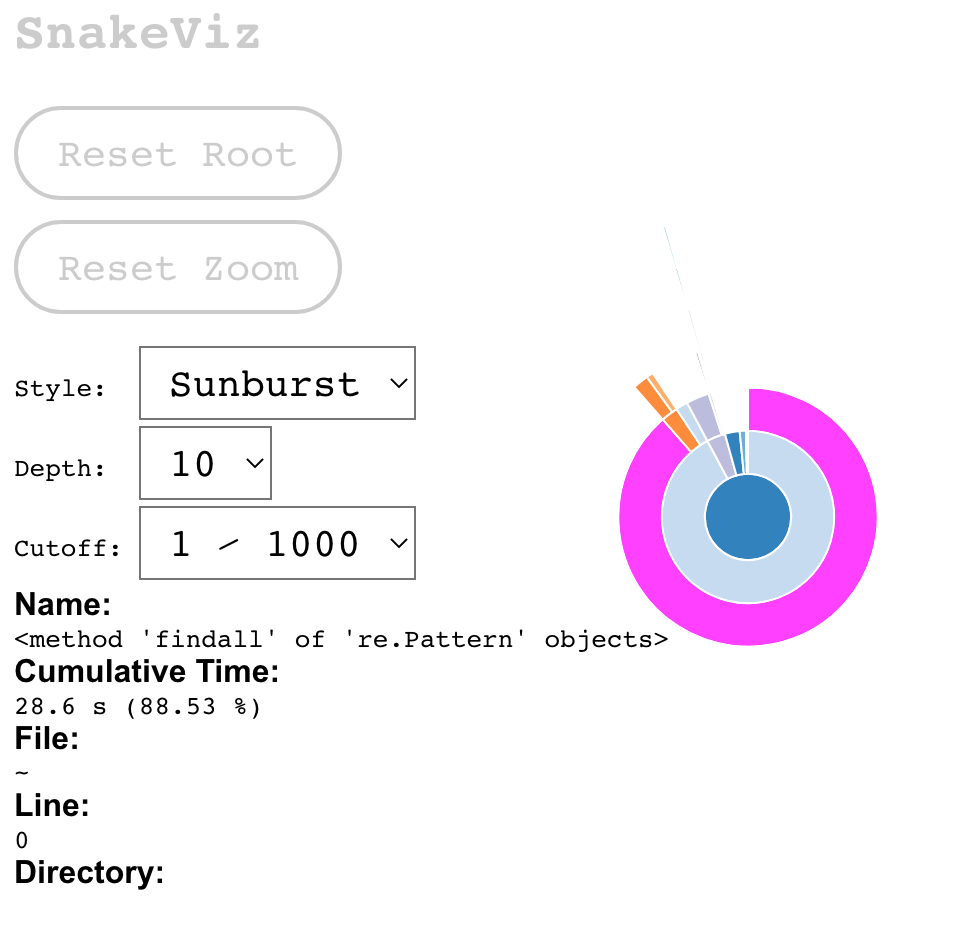
Kết quả tương tác của Snakeviz — biểu đồ icicle (bên trái) và sunburst (bên phải, có thể nói là khó đọc hơn). Bạn có thể di chuột và nhấp vào mọi lệnh gọi hàm để xem chi tiết của chúng. Từ trên xuống dưới là hệ thống phân cấp lồng nhau của các lệnh gọi của bạn và độ dài của dòng là thời gian tương đối mà mã dành để thực thi nó.

Chúng ta thấy rằng phần lớn thời gian thực thi là trong hàm findall, tức là thực hiện tìm kiếm bằng biểu thức chính quy. Điều đó có nghĩa là, nếu chúng ta muốn tăng tốc độ code, chúng ta cần tập trung vào việc tăng tốc hàm đó vì nó là yếu tố gây tắc nghẽn (bottleneck) chứ không phải các phần khác của code.
3.2. gprof2dot — Dễ đọc và linh hoạt
Gprof2dot cung cấp hình ảnh trực quan dễ đọc hơn dưới dạng sơ đồ luồng, được lưu dưới dạng tệp hình ảnh, do đó dễ dàng chia sẻ (và tự động hóa nếu cần thiết) kết quả. Tuy nhiên, nó không tương tác và yêu cầu cài đặt Graphviz trong hệ thống.
Để cài đặt gprof2dot, chỉ cần sử dụng lệnh pip install gprof2dot.
Để tạo hình ảnh đầu ra với kết quả profiling, sử dụng lệnh sau:
python -m gprof2dot -f pstats <profiling-results-file> | dot -Tpng -o output.png
Đầu tiên, chúng ta biểu diễn hệ thống phân cấp của các lệnh gọi hàm dưới dạng một đồ thị ở định dạng dot, tiếp theo tạo một hình ảnh — hình ảnh hóa của đồ thị đó. Lệnh dot hỗ trợ các định dạng đầu ra khác nhau, bao gồm .jpg và .svg, và đầu ra của gprof2dot cũng có thể tùy chỉnh cao.
Hãy xem nó trông như thế nào.
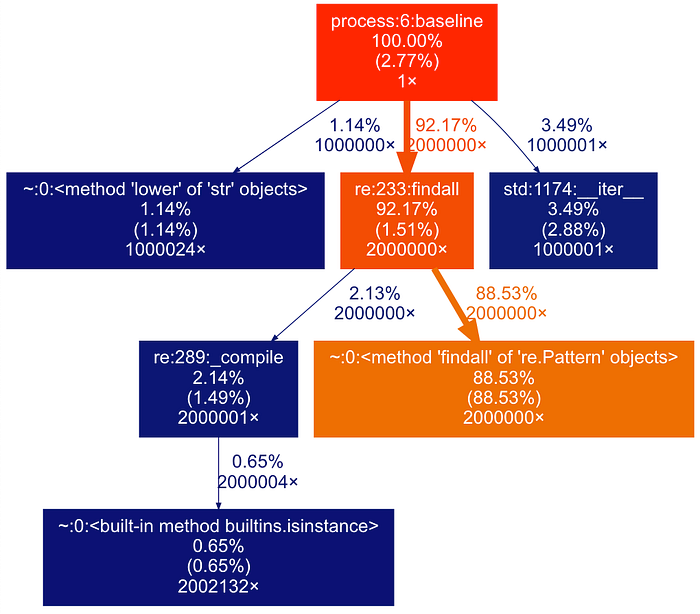
Biểu diễn đồ thị của hệ thống phân cấp thực thi hàm trong mã của chúng ta. Các phần trăm cho thấy tổng phần thời gian thực thi và tỷ lệ phần trăm tương ứng được sử dụng trong hàm, , nhưng chỉ bao gồm mã của chính hàm đó. Giá trị cuối cùng là số lần hàm được gọi trong mã.
Biểu đồ cho thấy tìm kiếm bằng biểu thức chính quy chiếm tới 88% tổng thời gian thực hiện, có thể nói là dễ đọc hơn nhiều, do đó chúng ta cần tập trung vào việc làm cho nó nhanh hơn.
Nếu bạn không có quyền truy cập vào Graphviz (lệnh dot), bạn có thể sử dụng gói Python tương ứng cho Graphviz (pip install graphviz) và một script Python đơn giản để tạo kết quả.
-
Chúng ta sẽ lưu kết quả
gprof2dotvào một tệp.dot:python -m gprof2dot -f pstats file.prof > file.dot -
Tạo một hình ảnh từ tệp .dot này bằng cách sử dụng đoạn mã sau:
import graphviz
def make_png(input_file_name, output_file_name):
dot = graphviz.Source.from_file(input_file_name)
dot.render(outfile=output_file_name)
if __name__ == '__main__':
make_png('file.dot', 'file.svg') # also supports .png, .jpg, etc.
4. Cải tiến code
Hãy tăng tốc code bằng cách kết hợp hai biểu thức chính quy thành một:
def single_pattern():
num_total_matches = 0
pattern = r"[0-9][rb]ob" # We now have only one search instead of two
with open('random.txt', 'rt') as f:
for line in tqdm(f, total=1_000_000):
line = line.lower()
# Find all occurrences of the pattern in the string
matches = re.findall(pattern, line)
# Count the number of matches
num_matches = len(matches)
num_total_matches += num_matches
return num_total_matches
Như bạn có thể thấy tốc độ đã được cải tiện ~ 2 lần.

% thời gian thực hiện findall giảm xuống (88% -> 81,5%)
Việc phân tích code mới xác nhận rằng đó là lựa chọn đúng đắn — tỷ lệ thời gian mà hàm chính findall chiếm đã giảm và tăng lên cho tất cả các hàm khác (khoảng 2 lần).
Nếu chúng ta thực hiện tất cả ba ý tưởng khác thay vì tập trung vào điểm nghẽn, thời gian chạy sẽ là 32 giây, bằng với thời gian ban đầu! Có thể thấy, điều này đã lãng phí rất nhiều thời gian và công sức! Đây chính là lý do tại sao việc tập trung vào các điểm nghẽn là quan trọng.
def wasted_efforts():
num_total_matches = 0
# We use compiled regular expressions
pattern1 = re.compile(r"[0-9]{1}rob", flags=re.IGNORECASE)
# We also use case case-insensitivity instead of changing the lines
pattern2 = re.compile(r"[0-9]{1}bob", flags=re.IGNORECASE)
with open('random.txt', 'rt') as f:
# We load lines into a chunk and process it in 1 go
chunk = []
for line in tqdm(f, total=1_000_000):
chunk.append(line)
if len(chunk) == 1000:
chunk_str = ''.join(chunk)
for pattern in [pattern1, pattern2]:
# Find all occurrences of the pattern in the string
matches = re.findall(pattern, chunk_str)
# Count the number of matches
num_matches = len(matches)
num_total_matches += num_matches
chunk = []
# But despite our efforts, this code is still as slow as the original
return num_total_matches
5. Đa xử lý
Hàm findall vẫn là điểm nghẽn. Tuy nhiên, trong ví dụ đơn giản này, chúng ta chỉ cần thực hiện một điều đơn giản để cải thiện nó: song song hóa code. Các kết quả tìm kiếm trong các chuỗi khác nhau không phụ thuộc lẫn nhau, vì vậy chúng ta có thể tìm kiếm chúng song song. Làm thế nào để thực hiện điều đó?
Cách đơn giản nhất là tạo một Process Pool - một đối tượng điều khiển nhiều tiến trình Python song song, tất cả đều chạy đồng thời. Nếu có một danh sách các giá trị và một hàm để áp dụng cho từng giá trị, chúng ta chỉ cần gọi phương thức map của pool và nó sẽ chạy hàm của chúng ta song song trên tất cả các giá trị.
from multiprocessing import Pool
def calc_num_matches(string):
# We create a separate function for our Pool object
# It will be applied in parallel to every line in the file
pattern = r"[0-9]{1}[rb]ob"
return len(re.findall(pattern, string))
def chunks_single_pool():
num_total_matches = 0
pool = Pool(8) # number of processes, should be <= number of your CPU cores
with open('random.txt', 'rt') as f:
chunk = []
# We load lines in a list
for line in tqdm(f, total=1_000_000):
line = line.lower()
chunk.append(line)
if len(chunk) == 1000:
# And then we apply our `calc_num_matches` function to every line in parallel
num_ind_matches = pool.map(calc_num_matches, chunk)
# And add together all the independt matches
num_matches = sum(num_ind_matches)
num_total_matches += num_matches
chunk = []
return num_total_matches
Hãy cùng xem nào… 6,1 giây! Đây là một kỷ lục mới. Nó nhanh hơn 2,2 lần so với giải pháp tối ưu và nhanh hơn ~5 lần so với giải pháp gốc! Hãy cùng xem kết quả phân tích:

Tỷ lệ tìm kiếm regex tiếp tục giảm (khối màu xanh lá cây)

Snakeviz hiển thị hình ảnh tương tự cho mã có xử lý đa luồng.
Chúng xác nhận rằng việc tìm kiếm bằng biểu thức chính quy bây giờ chiếm khoảng 2/3 tổng thời gian, ít hơn nhiều so với phiên bản ban đầu.
6. Một số điểm bạn cần chú ý
6.1. Đa xử lý
-
Profiler không còn biết điều gì đang xảy ra bên trong các tiến trình con thực hiện tìm kiếm - Nó chỉ hiển thị thời gian chờ đợi 4 giây để tất cả các tiến trình con hoàn thành, nhưng profiler không thể truy cập vào code đang được thực thi bên trong các tiến trình con đó. Lý do là vì các tiến trình con này hoạt động như những chương trình riêng biệt, chỉ được kết nối lỏng lẻo với tiến trình Python chính.
-
Nếu bạn muốn phân tích hiệu suất code chạy trong các tiến trình con, bạn cần cài đặt decorator @profile vào bên trong hàm/code
6.2. Đa luồng
Thông thường, bạn không cần phải viết trực tiếp code đa luồng (multi-threaded) trong Python do tính ứng dụng hạn chế của nó, vì Global Interpreter Lock - GIL chỉ cho phép một luồng thực thi mã Python tại một thời điểm (trong một tiến trình Python đơn).
Tuy nhiên, nếu bạn đang làm việc với nhiều thư viện không phải Python (ví dụ: NumPy, PyTorch, scipy) hoặc với I/O nặng (liên lạc web), thì hầu hết thời gian chạy code của bạn sẽ ở bên ngoài trình thông dịch Python, được viết bằng C, C++, Fortran, v.v.
Trong hai trường hợp này, việc sử dụng nhiều luồng có thể hữu ích. Bạn cần lưu ý rằng cả hai module phân tích hiệu suất tích hợp sẵn cho Python - profile và cProfile - chỉ phân tích luồng chính của ứng dụng. Nếu bạn muốn phân tích hiệu suất code được thực thi bởi các luồng khác ngoài luồng chính, bạn có thể thử chạy profiler bên trong hàm mà các luồng của bạn sẽ thực thi hoặc sử dụng một số công cụ phân tích hiệu suất của bên thứ ba như Yappi hoặc VizTracer.
6.3. Tính toán GPU
Nếu bạn đang sử dụng GPU để tính toán, hãy nhận thức rằng nó là một thiết bị riêng biệt trong hệ thống của bạn và chạy không đồng bộ với CPU. Vì vậy, khi thực thi một số mã trên GPU, bạn cần rất cẩn thận khi đo thời gian thực thi vì mã Python của bạn không biết điều gì đang xảy ra trong GPU. Nó chỉ có thể yêu cầu GPU làm điều gì đó và chờ GPU hoàn thành.
Hãy xem đoạn code sau:.
import torch
from profilehooks import profile
def compute_big_sum(tensor: torch.Tensor):
# do a bunch of expensive computations, that all output a single number
a = tensor.sum()
b = tensor.pow(2).sum()
c = tensor.sqrt().sum()
sum_all = a + b + c
sum_all_cpu = sum_all.cpu() # move the value to CPU memory
# return a sum of all the operations (scalar)
return sum_all_cpu
if __name__ == '__main__':
# Create a big matrix of random number, already in GPU memory
X = torch.rand((10000, 10000), dtype=torch.float64, device='cuda:0')
res = compute_big_sum(X)
print(float(res))
Chúng ta vừa tạo một ma trận lớn kích thước 10000x10000 trong PyTorch (trên GPU) và sau đó phân tích hiệu suất của hàm thực hiện qua các bước sau:
1. Tổng của tất cả các phần tử
2. Tổng của bình phương tất cả các phần tử
3. Tổng của căn bậc hai của tất cả các phần tử
4. Tổng của ba tổng trước đó
Hàm này trả về một số duy nhất làm đầu ra.
Theo bạn, dòng code nào sẽ mất nhiều thời gian nhất?

Thật ngạc nhiên, đó là phương thức .cpu(), phương thức di chuyển dữ liệu từ bộ nhớ GPU sang bộ nhớ CPU! Nhưng có vẻ không hợp lý. Chúng ta chỉ đang di chuyển 8 byte dữ liệu! Liệu việc chuyển bộ nhớ có chậm đến vậy?
Câu trả lời là không.
Bởi vì dưới lớp của PyTorch, các phép tính được thực hiện bởi CUDA trên GPU, một thiết bị riêng biệt so với CPU. Khi bạn sử dụng các hàm như .sum() hay torch.pow() hoặc bất kỳ hàm nào khác, Python chỉ yêu cầu GPU bắt đầu tính toán nhưng không thực sự chờ chúng hoàn thành! Điều này có nghĩa là trình thông dịch Python sẽ khởi chạy phép tính và ngay lập tức chuyển sang dòng mã tiếp theo.
Việc chờ đợi xảy ra trong phương thức .cpu(), phương thức di chuyển dữ liệu từ bộ nhớ GPU sang bộ nhớ CPU. Do đó, nó buộc phải chờ cho đến khi kết quả của tất cả các phép tính trước đó có sẵn trong bộ nhớ GPU — tức là tất cả các hàm mà chúng ta đã áp dụng cho ma trận lớn đã hoàn thành việc thực thi.
Nhưng làm thế nào để chúng ta phân tích hiệu suất của điều đó?
-
Sử dụng trình phân tích hiệu suất tích hợp của PyTorch, hỗ trợ phân tích hiệu suất các thao tác trên nhiều thiết bị;
-
Nếu bạn không quan tâm đến việc mỗi thao tác riêng lẻ trên GPU mất bao lâu (hoặc bạn chỉ có 1 thao tác), bạn có thể thêm
torch.cuda.synchronize()vào code của mình ngay sau khi bắt đầu tất cả các phép tính trên GPU, điều này sẽ buộc PyTorch chờ cho đến khi tất cả các thao tác trên GPU hoàn thành.
Hãy xem kết quả phân tích hiệu suất của chúng ta trông như thế nào với dòng code này:
def compute_big_sum(tensor: torch.Tensor):
a = tensor.sum()
b = tensor.pow(2).sum()
c = tensor.sqrt().sum()
sum_all = a + b + c
torch.cuda.synchronize() # add this after all your GPU operations
# to ensure correct time measurements
sum_all_cpu = sum_all.cpu()
return sum_all_cpu
Đoạn mã cho hàm compute_big_sum đã được điều chỉnh sẽ như sau:
Lời kết
Python tuy mạnh mẽ nhưng đôi khi có thể chậm do các yếu tố như GIL và cách quản lý bộ nhớ. Để khắc phục, hãy sử dụng các công cụ profiling như cProfile và các thư viện như Yappi, tận dụng đa luồng, đa tiến trình, và GPU khi cần. Tối ưu hóa mã không chỉ cải thiện tốc độ mà còn giữ cho mã dễ đọc và bảo trì. Hãy liên tục học hỏi và điều chỉnh sẽ giúp bạn tối ưu hóa mã Python hiệu quả.
Nguồn: Maksym Bekuzarov
TẠO TÀI KHOẢN MỚI: XEM FULL “1 TÁCH CODEFEE” - NHẬN SLOT TƯ VẤN CV TỪ CHUYÊN GIA - CƠ HỘI RINH VỀ VOUCHER 200K





