
System Design là một trong những nội dung thường được hỏi khi tham gia phỏng vấn trong các công ty công nghệ lớn. Vì thế, trong bài viết này VietnamWorks inTECH sẽ giới thiệu đến các Dev khái niệm về 16 system design vô cùng quan trọng, giúp bạn tự tin áp dụng chúng trong cuộc phỏng vấn tiếp theo.
1. Domain Name System (DNS)
Domain Name System - Hệ thống phân giải tên miền (DNS) là thành phần cơ bản của cơ sở hạ tầng internet giúp dịch các tên miền thân thiện với con người thành địa chỉ IP tương ứng của chúng. Nó hoạt động giống như một danh bạ Internet, cho phép người dùng truy cập các trang web và dịch vụ bằng cách nhập các tên miền dễ nhớ, chẳng hạn như www.vietnamworksintech thay vì các địa chỉ IP dạng số như “192.0.2.1” mà các máy tính sử dụng để nhận dạng lẫn nhau.
Khi bạn nhập tên miền vào trình duyệt web, DNS chịu trách nhiệm định vị địa chỉ IP được liên kết và chuyển yêu cầu của bạn đến đúng máy chủ. Quá trình bắt đầu bằng việc máy tính của bạn gửi truy vấn đến recursive resolver, sau đó chúng tìm kiếm một loạt server DNS, bắt đầu là root server, tiếp theo là server Top-Level Domain (TLD) và cuối cùng là authoritative nameserver. Sau khi tìm thấy địa chỉ IP, recursive resolver sẽ trả địa chỉ đó về máy tính của bạn, cho phép trình duyệt của bạn thiết lập kết nối với target server và truy cập nội dung mong muốn.

2. Load Balancer
Load Balancer - Cân bằng tải là một thiết bị hoặc phần mềm phân phối lưu lượng truy cập đến, trên nhiều server để đảm bảo sử dụng tài nguyên tối ưu, giảm độ trễ và duy trì tính sẵn sàng cao (high availability). Nó đóng một vai trò quan trọng trong việc mở rộng quy mô ứng dụng và quản lý khối lượng công việc của server một cách hiệu quả, đặc biệt là trong các tình huống có lưu lượng truy cập tăng đột biến hoặc phân bổ request không đồng đều giữa các server.
Cân bằng tải sử dụng các thuật toán khác nhau để xác định cách phân phối lưu lượng truy cập đến. Các thuật toán phổ biến bao gồm:
- Round Robin: Các request được phân phối tuần tự và đồng đều trên tất cả các server có sẵn theo chu kỳ.
- Least Connections: Bộ cân bằng tải sẽ chỉ định các request đến server có ít hoạt động nhất.
- IP Hash: Một hàm hash (hash-function) được sử dụng để xác định máy chủ nào có thể được chọn cho request kế tiếp (dựa trên IP của máy khách). Phương pháp này đảm bảo rằng các request của một máy khách cụ thể luôn được định tuyến đến cùng một server, giúp duy trì tính ổn định của session.
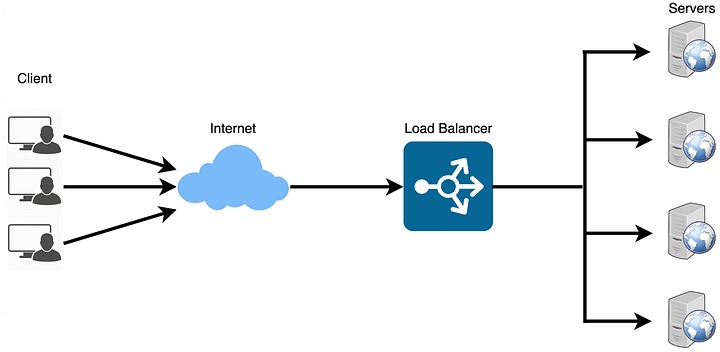
3. API Gateway
Đây là một server hoặc service đóng vai trò trung gian giữa các máy khách bên ngoài và các microservices nội bộ, hoặc các backend service dựa trên API của một ứng dụng. Phần mềm này giúp đơn giản hóa quá trình giao tiếp và cung cấp một điểm truy cập duy nhất để khách hàng truy cập các dịch vụ khác nhau.
Các chức năng chính của API Gateway bao gồm:
-
Request Routing: Nó chuyển các request API đến từ máy khách đến backend service hoặc microservice thích hợp, dựa trên các quy tắc và cấu hình được xác định trước.
-
Xác thực và ủy quyền: API Gateway có thể xử lý xác thực và ủy quyền người dùng, đảm bảo rằng chỉ những khách hàng được ủy quyền mới có thể truy cập dịch vụ. Nó có thể xác minh API keys, token hoặc thông tin xác thực khác trước khi định tuyến các request đến các backend service.
-
Giới hạn tốc độ và giảm hiệu suất: Để bảo vệ các backend service khỏi bị quá tải hoặc sử dụng quá mức, API Gateway có thể thực thi các giới hạn tốc độ hoặc giảm hiệu suất các request từ khách hàng dựa trên các chính sách được xác định trước.
-
Bộ nhớ đệm: Để giảm độ trễ và backend load, API Gateway có thể lưu vào bộ nhớ đệm các request được sử dụng thường xuyên, phân phát chúng trực tiếp cho máy khách mà không cần truy vấn các backend service.
-
Chuyển đổi request và response: API Gateway có thể sửa đổi các request và response, chẳng hạn như chuyển đổi định dạng dữ liệu, thêm/xóa tiêu đề hoặc sửa đổi tham số truy vấn để đảm bảo khả năng tương thích giữa máy khách và service.
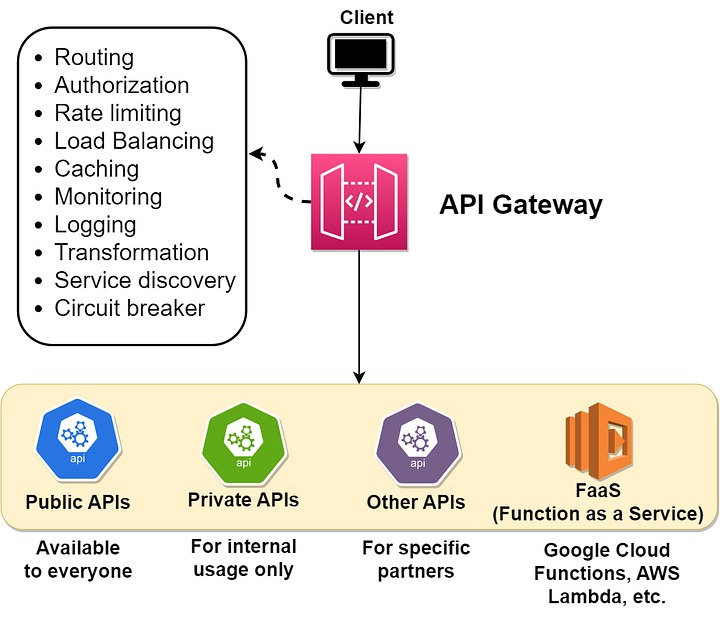
4. CDN
Content Delivery Network (CDN) là mạng lưới phân tán gồm các server lưu trữ và phân phối nội dung, chẳng hạn như hình ảnh, video, stylesheets và tập lệnh, tới người dùng từ các vị trí địa lý gần hơn. CDN được thiết kế để cải thiện hiệu suất, tốc độ và độ tin cậy của việc phân phối nội dung tới người dùng cuối, bất kể khoảng cách bao xa so với server gốc.
Đây là cách CDN hoạt động:
-
Khi người dùng request nội dung từ một trang web hoặc ứng dụng, request đó sẽ được chuyển hướng đến server CDN gần nhất, còn được gọi là edge server hay còn gọi là máy chủ biên.
-
Nếu máy chủ biên có nội dung request được lưu vào bộ nhớ đệm, nó sẽ trực tiếp phân phát nội dung đó cho người dùng. Điều này làm giảm độ trễ và cải thiện trải nghiệm người dùng vì nội dung được truyền đi một khoảng cách ngắn hơn.
-
Nếu nội dung không được lưu vào bộ nhớ đệm trên máy chủ biên, CDN sẽ truy xuất nội dung đó từ server gốc hoặc server CDN khác gần đó. Sau khi nội dung được tìm nạp, nó sẽ được lưu vào bộ đệm trên máy chủ biên và được cung cấp cho người dùng.
-
Để đảm bảo nội dung luôn được cập nhật, CDN luôn kiểm tra server gốc định kỳ để biết các thay đổi và cập nhật bộ đệm cho phù hợp.
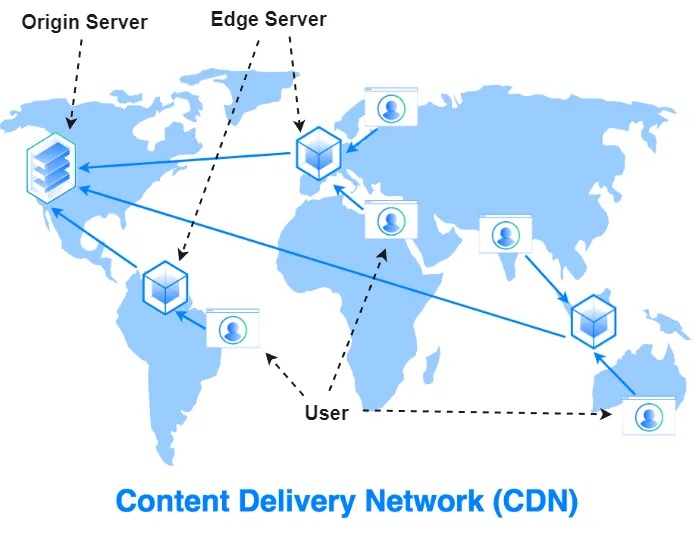
5. Forward Proxy vs. Reverse Proxy
Forward Proxy, còn được gọi là “proxy server” hoặc đơn giản là “proxy”, là server đặt trước một hoặc nhiều máy khách và hoạt động như một trung gian giữa máy khách và internet. Khi máy khách đưa ra request tới tài nguyên trên internet, request trước tiên sẽ được gửi đến forward proxy. Sau đó, chúng sẽ chuyển tiếp request tới internet thay mặt cho máy khách và trả về phản hồi cho máy khách.
Reverse Proxy là một server đặt trước một hoặc nhiều server web và hoạt động như một trung gian giữa các server web và Internet. Khi khách hàng đưa ra request tới một tài nguyên trên internet, yêu cầu đầu tiên sẽ được gửi đến reverse proxy. Sau đó, chúng sẽ chuyển tiếp request đến một trong các server web, server này sẽ trả về phản hồi cho reverse proxy. Reverse Proxy sau đó trả về phản hồi cho máy khách.
6. Caching (bộ đệm)
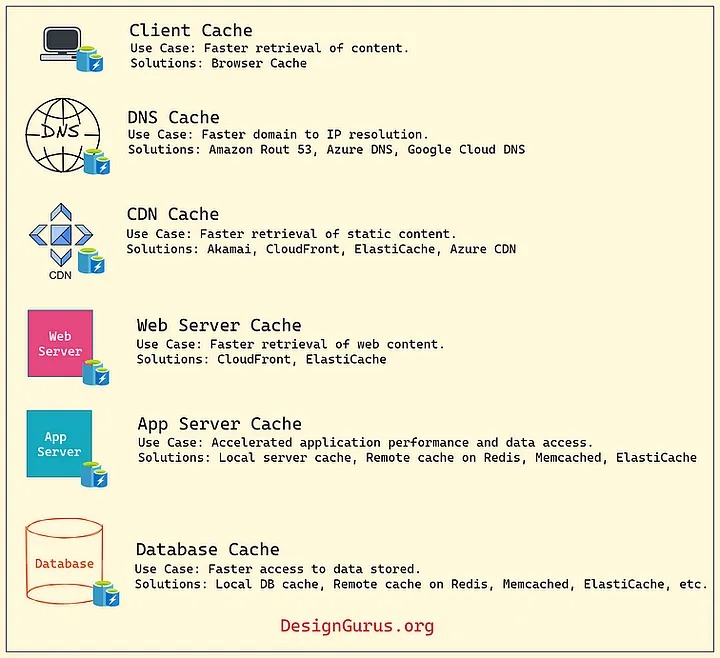
Bộ đệm là lớp lưu trữ tốc độ cao nằm giữa ứng dụng và nguồn dữ liệu ban đầu, chẳng hạn như cơ sở dữ liệu, file system hoặc remote web service. Khi dữ liệu được ứng dụng yêu cầu, dữ liệu đầu tiên sẽ được kiểm tra trong bộ đệm. Nếu dữ liệu được tìm thấy trong bộ đệm, nó sẽ được trả về ứng dụng. Nếu không tìm thấy dữ liệu trong bộ đệm, dữ liệu sẽ được lấy từ nguồn ban đầu, sau đó được lưu trong bộ đệm để sử dụng trong tương lai và trả về ứng dụng. Trong hệ thống phân tán, bộ nhớ đệm có thể được thực hiện ở nhiều nơi, ví dụ: Máy khách, DNS, CDN, Cân bằng tải, Cổng API, Server, Cơ sở dữ liệu, v.v.
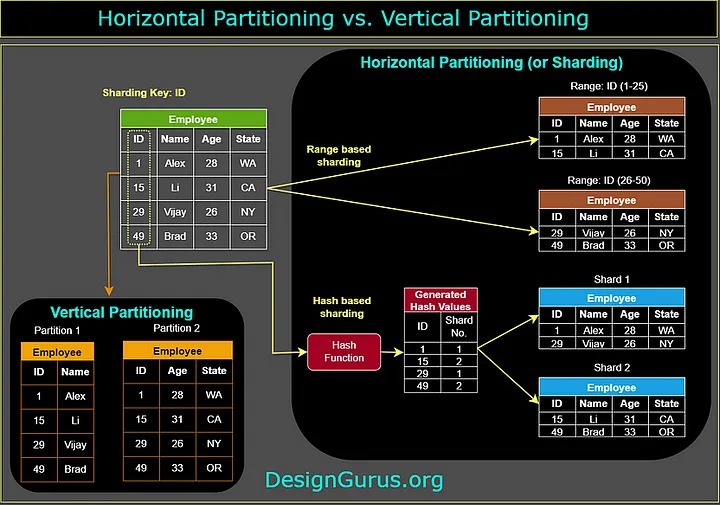
7. Data Partitioning
Trong cơ sở dữ liệu, phân vùng theo chiều ngang, còn được gọi là sharding, bao gồm việc chia các hàng của bảng thành các bảng nhỏ hơn và lưu trữ chúng trên các server hoặc phiên bản database khác nhau. Điều này được thực hiện để phân phối cơ sở dữ liệu trên nhiều server và giúp cải thiện hiệu suất.
Mặt khác, phân vùng theo chiều dọc bao gồm việc chia các cột của bảng thành các bảng riêng biệt. Điều này được thực hiện để giảm số lượng cột trong bảng và cải thiện hiệu suất của các truy vấn chỉ truy cập vào một số lượng cột nhỏ.
8. Database Replication (Sao chép cơ sở dữ liệu)
Database Replication (Sao chép cơ sở dữ liệu) là một kỹ thuật được sử dụng để duy trì nhiều bản sao của cùng một cơ sở dữ liệu trên các server hoặc vị trí khác nhau. Mục đích chính của việc sao chép cơ sở dữ liệu là cải thiện tính khả dụng, dự phòng và khả năng chịu lỗi của dữ liệu, đảm bảo hệ thống tiếp tục hoạt động ngay cả trong trường hợp lỗi phần cứng hoặc các sự cố khác.
Trong thiết lập sao chép cơ sở dữ liệu, một server đóng vai trò là cơ sở dữ liệu chính (master), trong khi các server khác hoạt động như bản sao (slaves). Quá trình này bao gồm việc đồng bộ hóa dữ liệu giữa cơ sở dữ liệu chính và các bản sao, để chúng đều có cùng thông tin cập nhật. Sao chép cơ sở dữ liệu mang lại một số lợi ích, bao gồm:
-
Hiệu suất được cải thiện: Bằng cách phân phối các truy vấn đọc giữa nhiều bản sao, bạn có thể giảm tải cho cơ sở dữ liệu chính và cải thiện thời gian phản hồi truy vấn.
-
Tính sẵn sàng cao: Trong trường hợp xảy ra lỗi hoặc ngừng hoạt động trên cơ sở dữ liệu chính, các bản sao có thể tiếp tục cung cấp dữ liệu, đảm bảo quyền truy cập vào ứng dụng không bị gián đoạn.
-
Bảo vệ dữ liệu nâng cao: Việc có nhiều bản sao của cơ sở dữ liệu trên các vị trí khác nhau giúp bảo vệ khỏi việc mất dữ liệu do lỗi phần cứng hoặc các lỗi khác.
-
Load Balancing: Bản sao có thể xử lý các truy vấn đọc, cho phép phân phối tải tốt hơn và giảm áp lực chung cho cơ sở dữ liệu chính.
9. Distributed Messaging Systems (Hệ thống phân tán message)
Hệ thống phân tán message cho phép trao đổi tin nhắn giữa nhiều ứng dụng, dịch vụ hoặc component có khả năng phân tán về mặt địa lý một cách đáng tin cậy, có thể mở rộng và có khả năng fault-tolerant. Chúng hỗ trợ giao tiếp bằng cách tách rời các component người gửi và người nhận, cho phép chúng phát triển và hoạt động độc lập. Hệ thống phân tán message đặc biệt hữu ích trong các hệ thống quy mô lớn hoặc phức tạp, chẳng hạn như các hệ thống được tìm thấy trong kiến trúc microservices hoặc môi trường điện toán phân tán, chẳng hạn như: Apache Kafka và RabbitMQ.
10. Microservices
Microservices là một kiểu kiến trúc trong đó ứng dụng được cấu trúc như một tập hợp các service nhỏ, được liên kết lỏng lẻo và có thể triển khai độc lập. Mỗi microservices chịu trách nhiệm về một phần chức năng hoặc domain cụ thể trong ứng dụng và giao tiếp với các microservices khác thông qua các API được xác định rõ. Cách tiếp cận này là được bắt đầu từ kiến trúc nguyên khối truyền thống (monolithic architecture), trong đó ứng dụng được xây dựng như một đơn vị duy nhất, liên kết chặt chẽ với nhau.
Các đặc điểm chính của microservice là:
-
Đơn nhiệm: Mỗi microservice tập trung vào một chức năng hoặc domain cụ thể, tuân thủ Nguyên tắc đơn nhiệm, giúp cho các dịch vụ dễ hiểu, phát triển và dễ bảo trì hơn.
-
Độc lập: Các microservices có thể được phát triển, triển khai và mở rộng quy mô độc lập với nhau. Điều này cho phép tăng tính linh hoạt trong quá trình phát triển, vì các nhóm có thể làm việc đồng thời trên các service khác nhau mà không ảnh hưởng đến toàn bộ hệ thống.
-
Phân cấp: Các microservices thường được phân cấp, với mỗi service sở hữu dữ liệu và bussiness logic của riêng nó. Điều này khuyến khích sự tách biệt các mối quan tâm và cho phép các nhóm đưa ra quyết định cũng như lựa chọn công nghệ phù hợp nhất với request cụ thể.
-
Giao tiếp: Các microservices giao tiếp với nhau bằng các giao thức Lightweight như HTTP/REST, gRPC hoặc message queues. Điều này thúc đẩy khả năng tương tác và giúp tích hợp các service mới hoặc thay thế các service hiện có dễ dàng hơn.
-
Fault Tolerance: Vì các microservices là độc lập nên một service bị lỗi sẽ không kéo theo toàn bộ hệ thống bị lỗi. Điều này có thể giúp cải thiện khả năng phục hồi tổng thể của ứng dụng.
11. NoSQL Databases
NoSQL Databases hoặc cơ sở dữ liệu “Not Only SQL”, là cơ sở dữ liệu phi quan hệ được thiết kế để lưu trữ, quản lý và truy xuất dữ liệu phi cấu trúc hoặc bán cấu trúc. Chúng cung cấp một giải pháp thay thế cho cơ sở dữ liệu quan hệ truyền thống dựa trên dữ liệu có cấu trúc và các lược đồ được xác định trước. Cơ sở dữ liệu NoSQL đã trở nên phổ biến nhờ tính linh hoạt, khả năng mở rộng và khả năng xử lý khối lượng dữ liệu lớn, khiến chúng rất phù hợp cho các ứng dụng hiện đại, xử lý dữ liệu lớn và phân tích thời gian thực.
Cơ sở dữ liệu NoSQL có thể được phân thành bốn loại chính:
-
Document-Based (cơ sở dữ liệu dạng tài liệu): Các cơ sở dữ liệu này lưu trữ dữ liệu trong các cấu trúc giống như tài liệu, chẳng hạn như JSON hoặc BSON. Mỗi tài liệu độc lập và có thể có cấu trúc riêng, giúp chúng phù hợp để xử lý những dữ liệu không đồng nhất. Ví dụ về cơ sở dữ liệu NoSQL dựa trên tài liệu bao gồm MongoDB và Couchbase.
-
Key-Value (khóa - giá trị): Các cơ sở dữ liệu này lưu trữ dữ liệu dưới dạng cặp khóa-giá trị, trong đó khóa đóng vai trò là mã định danh duy nhất và giá trị chứa dữ liệu liên quan. Cơ sở dữ liệu khóa-giá trị có hiệu quả cao đối với các thao tác đọc và ghi đơn giản, đồng thời chúng có thể dễ dàng được phân vùng và thu nhỏ theo chiều ngang. Ví dụ về cơ sở dữ liệu NoSQL khóa-giá trị bao gồm Redis và Amazon DynamoDB.
-
Column-Family: Các cơ sở dữ liệu này lưu trữ dữ liệu theo họ cột, là các nhóm cột có liên quan. Chúng được thiết kế để xử lý khối lượng công việc ghi nhiều và có hiệu quả cao khi đã biết các truy vấn dữ liệu bằng các phím hàng và cột, ví dụ như Apache Cassandra hay HBase.
-
Graph-Based: Các cơ sở dữ liệu này được thiết kế để lưu trữ và truy vấn dữ liệu có mối quan hệ phức tạp và cấu trúc liên kết với nhau, chẳng hạn như mạng xã hội hoặc hệ thống đề xuất. Cơ sở dữ liệu đồ thị sử dụng các node, edge và thuộc tính để biểu diễn và lưu trữ dữ liệu, giúp việc thực hiện các thao tác duyệt phức tạp và truy vấn dựa trên mối quan hệ trở nên dễ dàng hơn, ví dụ như Neo4j và Amazon Neptune.

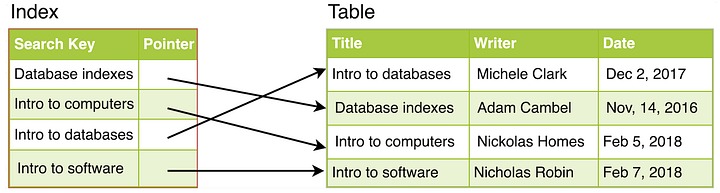
12. Database Index
Database Index là cấu trúc dữ liệu giúp cải thiện tốc độ và hiệu quả của các hoạt động truy vấn trong cơ sở dữ liệu. Chúng hoạt động tương tự như mục lục, cho phép hệ thống quản lý cơ sở dữ liệu (DBMS) nhanh chóng xác định vị trí dữ liệu được liên kết với một giá trị, hoặc tập hợp giá trị cụ thể mà không cần phải tìm kiếm qua từng hàng trong bảng. Bằng cách cung cấp đường dẫn trực tiếp đến dữ liệu mong muốn, các index (lập chỉ mục) có thể giảm đáng kể thời gian cần thiết để truy xuất thông tin từ cơ sở dữ liệu.
Các index thường được xây dựng trên một hoặc nhiều cột của bảng cơ sở dữ liệu. Loại index phổ biến nhất là B-tree index, tổ chức dữ liệu theo cấu trúc cây phân cấp, cho phép thực hiện các thao tác tìm kiếm, chèn và xóa nhanh chóng. Ngoài ra còn có các loại index khác như bitmap và hash.
Mặc dù các index có thể cải thiện đáng kể hiệu năng truy vấn nhưng chúng cũng có một số nhược điểm:
-
Dung lượng lưu trữ: Các index tiêu tốn thêm dung lượng lưu trữ khi chúng tạo và duy trì các cấu trúc dữ liệu riêng biệt cùng với dữ liệu của bảng gốc.
-
Hiệu suất ghi: Khi dữ liệu được chèn, cập nhật hoặc xóa trong bảng, các index liên quan cũng phải được cập nhật, điều này có thể làm chậm hoạt động ghi.
13. Distributed File Systems
Distributed File Systems là giải pháp lưu trữ được thiết kế để quản lý và cung cấp quyền truy cập vào tệp và thư mục trên nhiều server, nodes hoặc máy, thường được phân phối qua mạng. Chúng cho phép người dùng và ứng dụng truy cập và thao tác với các tệp như thể chúng được lưu trữ trên local file system, mặc dù các tệp thực tế có thể được lưu trữ vật lý trên nhiều server từ xa. Distributed File Systems thường được sử dụng trong môi trường điện toán phân tán hoặc quy mô lớn để cung cấp khả năng chịu lỗi (fault tolerance), tính sẵn sàng cao và cải thiện hiệu suất.
14. Notification System
Chúng được sử dụng để gửi thông báo hoặc cảnh báo cho người dùng, chẳng hạn như email, thông báo đẩy hoặc tin nhắn văn bản.
15. Full-text Search
Full-text Search cho phép người dùng tìm kiếm các từ hoặc cụm từ cụ thể trong ứng dụng hoặc trang web. Khi người dùng truy vấn, ứng dụng hoặc trang web sẽ trả về kết quả phù hợp nhất. Để thực hiện điều này một cách nhanh chóng và hiệu quả, Full-text Search dựa vào Inverted Index, nghĩa là chúng sẽ maps các từ hoặc cụm từ tới tài liệu mà chúng xuất hiện. Elastic Search là một trong những hệ thống Full-text Search tiêu biểu.
16. Distributed Coordination Services
Distributed Coordination Services là các hệ thống được thiết kế để quản lý và điều phối hoạt động của các ứng dụng, dịch vụ hoặc nodes một cách đáng tin cậy, hiệu quả và có khả năng chịu lỗi. Chúng giúp duy trì tính nhất quán, xử lý đồng bộ hóa phân tán và quản lý cấu hình cũng như trạng thái của các thành phần khác nhau trong môi trường phân tán. Distributed Coordination Services đặc biệt hữu ích trong các hệ thống quy mô lớn hoặc phức tạp, chẳng hạn như các dịch vụ có trong kiến trúc microservices, môi trường điện toán phân tán hoặc cơ sở dữ liệu theo cụm. Một số hệ thống nổi bật: Apache ZooKeeper, etcd, Consul.
Dưới đây là danh sách các chủ đề phỏng vấn về design system phổ biến, các dev có thể tham khảo qua:
-
Thiết kế dịch vụ chia sẻ tệp như Google Drive hoặc Dropbox.
-
Thiết kế nền tảng truyền phát video
-
Thiết kế dịch vụ rút ngắn URL
-
Thiết kế trình thu thập dữ liệu web
-
Thiết kế Facebook Messenger
-
Thiết kế tìm kiếm Twitter
TẠO TÀI KHOẢN MỚI: XEM FULL “1 TÁCH CODEFEE” - NHẬN SLOT TƯ VẤN CV TỪ CHUYÊN GIA - CƠ HỘI RINH VỀ VOUCHER 200K





