Cấu trúc dữ liệu đang được sử dụng trong hầu hết các chương trình hoặc hệ thống phần mềm đã được phát triển. Hơn nữa, cấu trúc dữ liệu dựa trên các nguyên tắc cơ bản của Khoa học Máy tính và Kỹ thuật Phần mềm. Và cũng là một chủ đề chính khi nói đến các câu hỏi phỏng vấn Software Engineering. Do đó, là nhà phát triển, chúng ta phải có kiến thức tốt về cấu trúc dữ liệu.
Bài viết này sẽ giải thích ngắn gọn 05 cấu trúc dữ liệu thường được sử dụng mà mọi lập trình viên phải biết.
1. Mảng (Array)
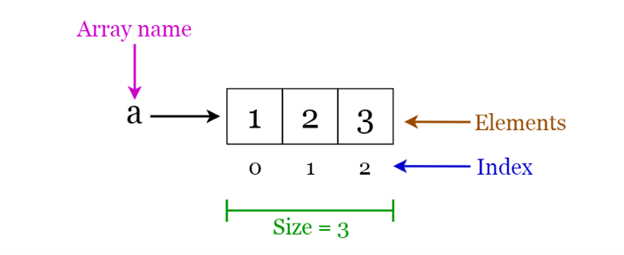
Mảng là một cấu trúc có kích thước cố định, có thể chứa các mục có cùng kiểu dữ liệu. Nó có thể là một mảng các số nguyên, một mảng số dấu phẩy động, một mảng chuỗi hoặc thậm chí một mảng mảng (chẳng hạn như mảng 2 chiều). Mảng được lập chỉ mục, nghĩa là có thể truy cập ngẫu nhiên.
Các phép toán mảng
-
Traverse: Đi qua các phần tử và in chúng.
-
Search: Tìm kiếm một phần tử trong mảng. Bạn có thể tìm kiếm phần tử theo giá trị hoặc chỉ số của nó
-
Update: Cập nhật giá trị của một phần tử hiện có tại một chỉ mục nhất định
Việc chèn các phần tử vào một mảng và xóa các phần tử khỏi một mảng không thể được thực hiện ngay lập tức vì các mảng có kích thước cố định. Nếu bạn muốn chèn một phần tử vào một mảng, trước tiên bạn sẽ phải tạo một mảng mới với kích thước tăng lên (kích thước hiện tại + 1), sao chép các phần tử hiện có và thêm phần tử mới. Tương tự đối với việc xóa với một mảng mới có kích thước giảm.
Ứng dụng của mảng
-
Được sử dụng làm khối xây dựng để xây dựng các cấu trúc dữ liệu khác như danh sách mảng, đống, hash table, vectơ và ma trận.
-
Được sử dụng cho các thuật toán sắp xếp khác nhau như sắp xếp chèn, sắp xếp nhanh, sắp xếp bong bóng và sắp xếp hợp nhất.
2. Danh sách được liên kết (Linked list)
Danh sách liên kết là một cấu trúc tuần tự bao gồm một chuỗi các mục theo thứ tự tuyến tính được liên kết với nhau. Do đó, bạn phải truy cập dữ liệu một cách tuần tự và không thể truy cập ngẫu nhiên. Danh sách được liên kết cung cấp cách biểu diễn các tập động đơn giản và linh hoạt.
Hãy xét các điều kiện sau về danh sách được liên kết.
-
Các phần tử trong danh sách liên kết được gọi là các nút.
-
Mỗi nút chứa một khóa và một con trỏ đến nút kế nhiệm của nó, được gọi là nút tiếp theo.
-
Thuộc tính có tên head trỏ đến phần tử đầu tiên của danh sách được liên kết.
-
Phần tử cuối cùng của danh sách liên kết được gọi là phần đuôi.

Sau đây là các loại danh sách liên kết có sẵn.
-
Danh sách liên kết đơn - Chỉ có thể thực hiện việc chuyển tải các mục theo hướng về phía trước.
-
Danh sách được liên kết kép - Việc chuyển tải các mục có thể được thực hiện theo cả hướng tiến và lùi. Các nút bao gồm một con trỏ bổ sung được gọi là trước, trỏ đến nút trước đó.
-
Danh sách liên kết hình tròn - Danh sách được liên kết trong đó con trỏ phổ biến của phần đầu trỏ đến phần đuôi và con trỏ tiếp theo của phần đuôi trỏ đến phần đầu.
Hoạt động của danh sách được liên kết
-
Search: Tìm phần tử đầu tiên có khóa k trong danh sách liên kết đã cho bằng tìm kiếm tuyến tính đơn giản và trả về một con trỏ đến phần tử này
-
Insert: Chèn một khóa vào danh sách được liên kết. Việc chèn có thể được thực hiện theo 3 cách khác nhau; chèn vào đầu danh sách, chèn vào cuối danh sách và chèn vào giữa danh sách.
-
Delete: Loại bỏ một phần tử x khỏi danh sách liên kết nhất định. Bạn không thể xóa một nút bằng một bước duy nhất. Việc xóa có thể được thực hiện theo 3 cách khác nhau; xóa ở đầu danh sách, xóa ở cuối danh sách và xóa ở giữa danh sách.
Các ứng dụng của danh sách liên kết
-
Được sử dụng để quản lý bảng ký hiệu trong thiết kế trình biên dịch.
-
Được sử dụng để chuyển đổi giữa các chương trình bằng Alt + Tab (được triển khai bằng Danh sách liên kết tròn).
3. Ngăn xếp (Stacks)
Stack là một cấu trúc LIFO (Last In First Out - phần tử được đặt ở vị trí cuối cùng có thể được truy cập đầu tiên) có trong nhiều ngôn ngữ lập trình. Cấu trúc này được đặt tên là “ngăn xếp” vì nó giống như một ngăn xếp trong thế giới thực - một chồng đĩa.

Hoạt động của Stack
Dưới đây là 2 hoạt động cơ bản có thể được thực hiện trên một stack.
-
Push: Chèn một phần tử vào đầu stack.
-
Pop: Xóa phần tử trên cùng và trả lại nó.

Hơn nữa, Stack có các chức năng bổ sung sau để kiểm tra trạng thái của nó.
-
Peek: Trả lại phần tử trên cùng của stack mà không xóa nó.
-
isEmpty: Kiểm tra xem stack có trống không.
-
isFull: Kiểm tra xem stack đã đầy chưa.
Ứng dụng của stack
-
Được sử dụng để đánh giá biểu thức (ví dụ: thuật toán shunting-yard để phân tích cú pháp và đánh giá các biểu thức toán học).
-
Được sử dụng để thực hiện các lời gọi hàm trong lập trình đệ quy.
4. Hàng đợi (Queue)
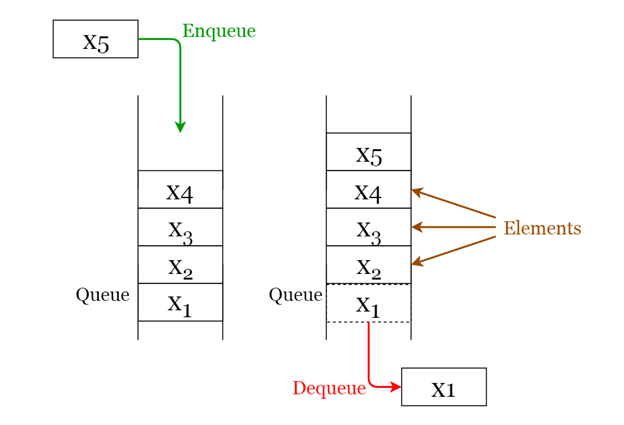
Queue là cấu trúc FIFO (First In First Out - phần tử được đặt ở vị trí đầu tiên có thể được truy cập ngay từ đầu) có trong nhiều ngôn ngữ lập trình. Cấu trúc này được đặt tên là “hàng đợi” vì nó giống như một hàng đợi trong thế giới thực - mọi người đang xếp hàng đợi.

Hoạt động của Queue
Có 02 hoạt động cơ bản được thực hiện bởi Queue:
-
Enqueue: Chèn một phần tử vào cuối hàng đợi.
-
Dequeue: Xóa phần tử khỏi đầu hàng đợi
Ứng dụng của Queue
-
Được sử dụng để quản lý các luồng trong đa luồng.
-
Được sử dụng để triển khai hệ thống xếp hàng (ví dụ: hàng đợi ưu tiên).
5. Bảng băm (Hash table)
Hash table là một cấu trúc dữ liệu lưu trữ các giá trị có các khóa được liên kết với mỗi giá trị đó. Hơn nữa, nó hỗ trợ tra cứu hiệu quả nếu chúng ta biết khóa được liên kết với giá trị. Do đó, nó rất hiệu quả trong việc chèn và tìm kiếm, bất kể kích thước của dữ liệu.
Direct addressing sử dụng ánh xạ 1-1 giữa các giá trị và khóa khi lưu trữ trong bảng. Tuy nhiên, có một vấn đề với cách tiếp cận này khi có một số lượng lớn các cặp khóa-giá trị (key-value). Bảng sẽ rất lớn với rất nhiều bản ghi và có thể không thực tế hoặc thậm chí không thể được lưu trữ, với bộ nhớ có sẵn trên một máy tính thông thường. Để tránh vấn đề này, chúng ta sử dụng hash table.
Hàm băm (Hash function)
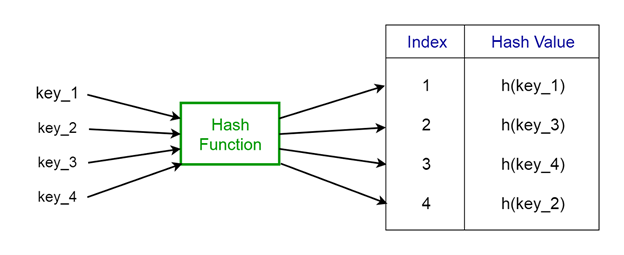
Một hàm đặc biệt có tên là hash function (h) được sử dụng để khắc phục vấn đề nói trên trong việc định địa chỉ trực tiếp.
Trong truy cập trực tiếp, một giá trị có khóa k được lưu trong khe k. Sử dụng hash function, chúng ta tính toán chỉ số của bảng (vị trí) mà mỗi giá trị đi đến. Giá trị được tính bằng cách sử dụng hash function cho một khóa nhất định được gọi là hash value cho biết chỉ mục của bảng mà giá trị được ánh xạ tới.
h(k) = k % m
-
h: hash function
-
k: key được xác định của hash value
-
m: kích cỡ của hash table (số lượng slot có sẵn). Một giá trị nguyên tố không gần với lũy thừa chính xác của 2 là một lựa chọn tốt cho m.
Xét hash function h (k) = k% 20, trong đó kích thước của hash table là 20. Cho một tập hợp các khóa, chúng ta muốn tính giá trị băm của mỗi khóa để xác định chỉ mục mà nó sẽ xuất hiện trong hash table. Xét chúng ta có các khóa sau, mã băm và chỉ mục hash table.
1 → 1% 20 → 1
5 → 5% 20 → 5
23 → 23% 20 → 3
63 → 63% 20 → 3
Từ hai ví dụ cuối cùng được đưa ra ở trên, chúng ta có thể thấy rằng xung đột có thể phát sinh khi hash function tạo ra cùng một chỉ mục cho nhiều hơn một khóa. Chúng ta có thể giải quyết các xung đột bằng cách chọn một hash function h phù hợp và sử dụng các kỹ thuật như chuỗi và định địa chỉ mở.
Các ứng dụng của hash table
-
Được sử dụng để triển khai các chỉ mục cơ sở dữ liệu.
-
Được sử dụng để triển khai các mảng kết hợp.
-
Được sử dụng để triển khai cấu trúc dữ liệu "set".
TẠO TÀI KHOẢN MỚI: XEM FULL “1 TÁCH CODEFEE” - NHẬN SLOT TƯ VẤN CV TỪ CHUYÊN GIA - CƠ HỘI RINH VỀ VOUCHER 200K

Information Systems (IS) Manager - ERP
Andros Vietnam - Công Ty TNHH Sản Xuất Trái Cây Hùng Phát

MES/ SCADA Developer
LVHA Manufacturing Ltd

Data & Insights Analyst
Turnkey Fba

Salesforce Developers
Capgemini Vietnam

IT Solutions Manager
Ziku Global LLC